 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Interpretable Concept-Based Models with Human Feedback
Paper and Code
Dec 04, 2020
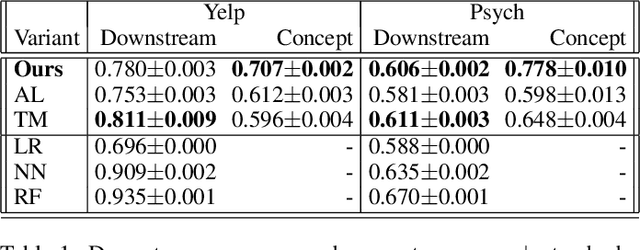
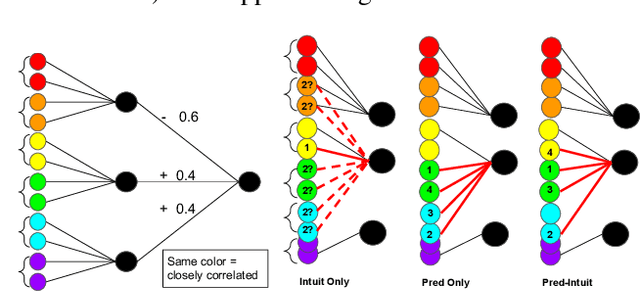

Machine learning models that first learn a representation of a domain in terms of human-understandable concepts, then use it to make predictions, have been proposed to facilitate interpretation and interaction with models trained on high-dimensional data. However these methods have important limitations: the way they define concepts are not inherently interpretable, and they assume that concept labels either exist for individual instances or can easily be acquired from users. These limitations are particularly acute for high-dimensional tabular features. We propose an approach for learning a set of transparent concept definitions in high-dimensional tabular data that relies on users labeling concept features instead of individual instances. Our method produces concepts that both align with users' intuitive sense of what a concept means, and facilitate prediction of the downstream label by a transparent machine learning model. This ensures that the full model is transparent and intuitive, and as predictive as possible given this constraint. We demonstrate with simulated user feedback on real prediction problems, including one in a clinical domain, that this kind of direct feedback is much more efficient at learning solutions that align with ground truth concept definitions than alternative transparent approaches that rely on labeling instances or other existing interaction mechanisms, while maintaining similar predictive performance.