 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Mobile Inference Benchmark: Why Mobile AI Benchmarking Is Hard and What to Do About It
Paper and Code
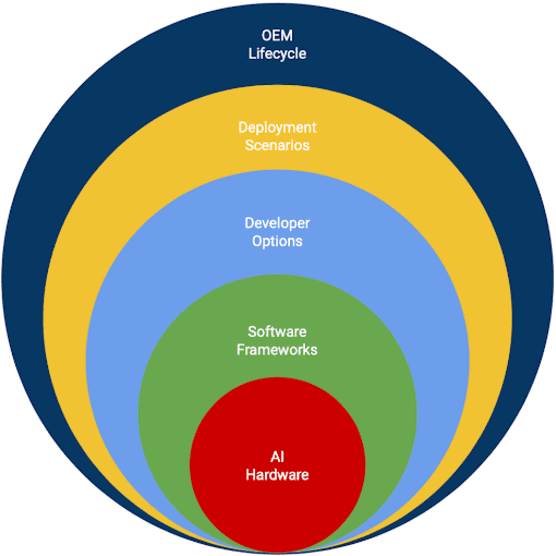

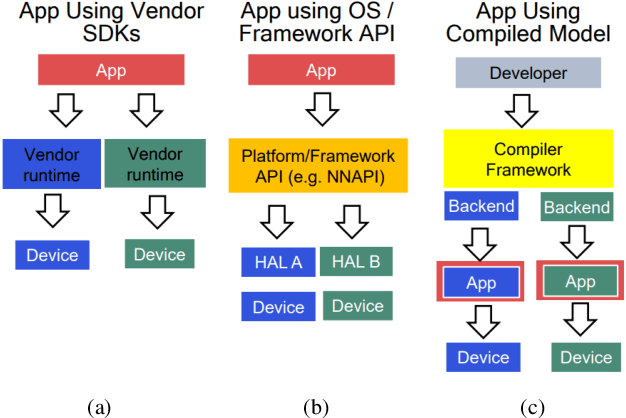
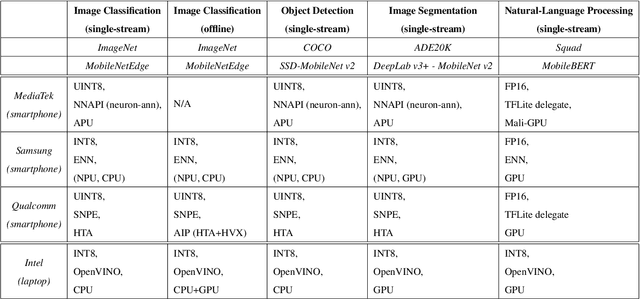
MLPerf Mobile is the first industry-standard open-source mobile benchmark developed by industry members and academic researchers to allow performance/accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. In this paper, we motivate the drive to demystify mobile-AI performance and present MLPerf Mobile's design considerations, architecture, and implementation. The benchmark comprises a suite of models that operate under standard models, data sets, quality metrics, and run rules. For the first iteration, we developed an app to provide an "out-of-the-box" inference-performance benchmark for computer vision and natural-language processing on mobile devices. MLPerf Mobile can serve as a framework for integrating future models, for customizing quality-target thresholds to evaluate system performance, for comparing software frameworks, and for assessing heterogeneous-hardware capabilities for machine learning, all fairly and faithfully with fully reproducible results.