 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Explaining Structures Improve NLP Models
Paper and Code
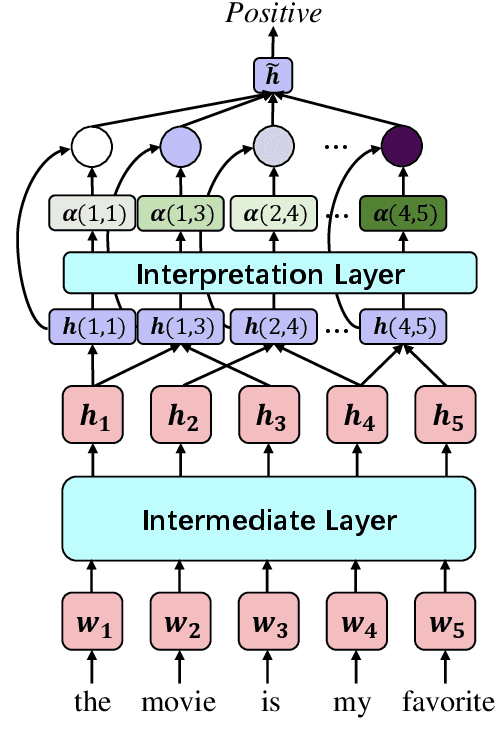
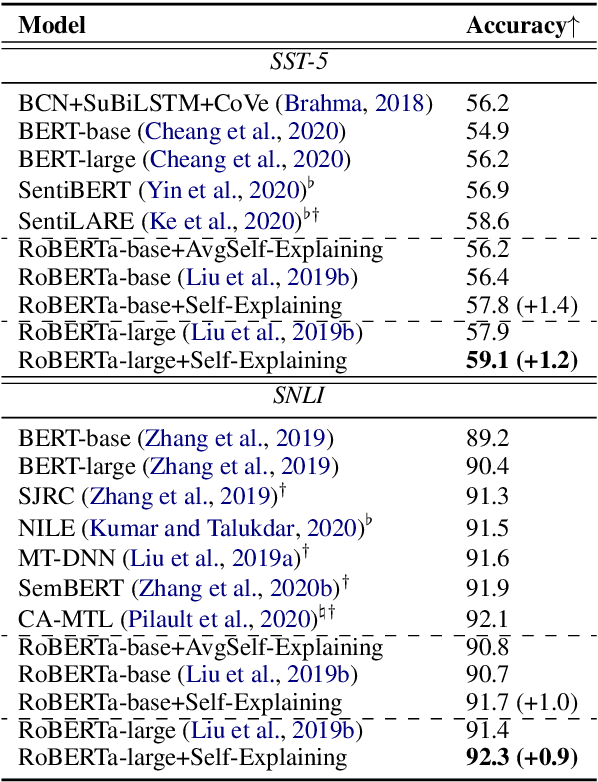

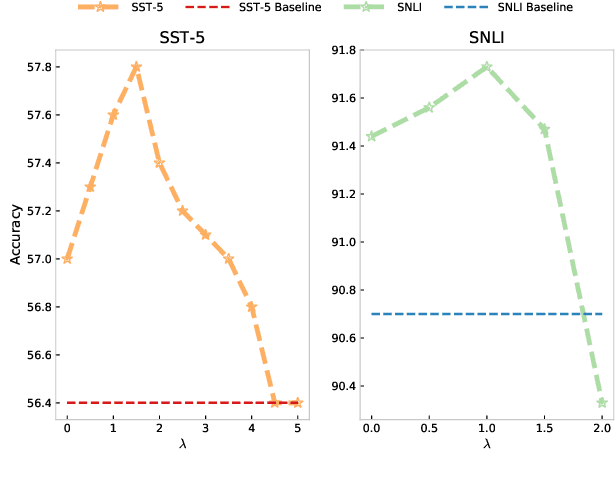
Existing approaches to explaining deep learning models in NLP usually suffer from two major drawbacks: (1) the main model and the explaining model are decoupled: an additional probing or surrogate model is used to interpret an existing model, and thus existing explaining tools are not self-explainable; (2) the probing model is only able to explain a model's predictions by operating on low-level features by computing saliency scores for individual words but are clumsy at high-level text units such as phrases, sentences, or paragraphs. To deal with these two issues, in this paper, we propose a simple yet general and effective self-explaining framework for deep learning models in NLP. The key point of the proposed framework is to put an additional layer, as is called by the interpretation layer, on top of any existing NLP model. This layer aggregates the information for each text span, which is then associated with a specific weight, and their weighted combination is fed to the softmax function for the final prediction. The proposed model comes with the following merits: (1) span weights make the model self-explainable and do not require an additional probing model for interpretation; (2) the proposed model is general and can be adapted to any existing deep learning structures in NLP; (3) the weight associated with each text span provides direct importance scores for higher-level text units such as phrases and sentences. We for the first time show that interpretability does not come at the cost of performance: a neural model of self-explaining features obtains better performances than its counterpart without the self-explaining nature, achieving a new SOTA performance of 59.1 on SST-5 and a new SOTA performance of 92.3 on SNLI.