 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-efficient L0-L2 constrained structure learning of sparse Ising models
Paper and Code

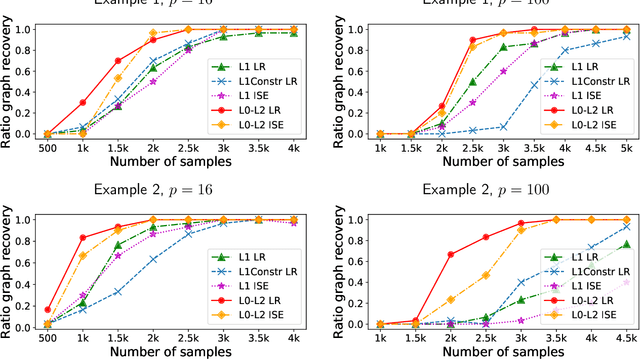
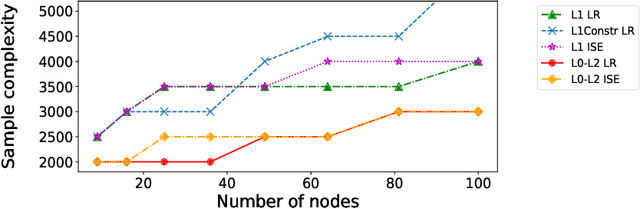
We consider the problem of learning the underlying graph of a sparse Ising model with $p$ nodes from $n$ i.i.d. samples. The most recent and best performing approaches combine an empirical loss (the logistic regression loss or the interaction screening loss) with a regularizer (an L1 penalty or an L1 constraint). This results in a convex problem that can be solved separately for each node of the graph. In this work, we leverage the cardinality constraint L0 norm, which is known to properly induce sparsity, and further combine it with an L2 norm to better model the non-zero coefficients. We show that our proposed estimators achieve an improved sample complexity, both (a) theoretically -- by reaching new state-of-the-art upper bounds for recovery guarantees -- and (b) empirically -- by showing sharper phase transitions between poor and full recovery for graph topologies studied in the literature -- when compared to their L1-based counterparts.