 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFMO: Deblurring and Shape Recovery of Fast Moving Objects
Paper and Code

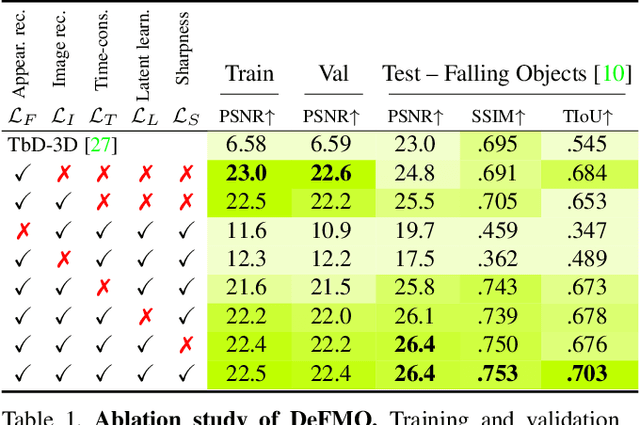
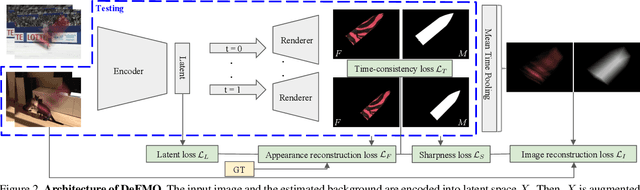
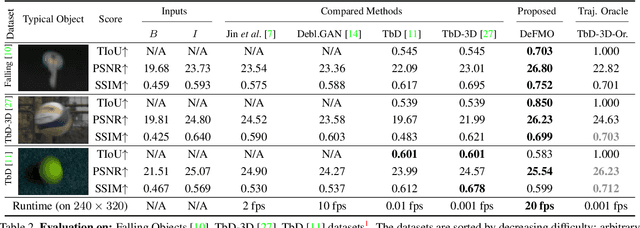
Objects moving at high speed appear significantly blurred when captured with cameras. The blurry appearance is especially ambiguous when the object has complex shape or texture. In such cases, classical methods, or even humans, are unable to recover the object's appearance and motion. We propose a method that, given a single image with its estimated background, outputs the object's appearance and position in a series of sub-frames as if captured by a high-speed camera (i.e. temporal super-resolution). The proposed generative model embeds an image of the blurred object into a latent space representation, disentangles the background, and renders the sharp appearance. Inspired by the image formation model, we design novel self-supervised loss function terms that boost performance and show good generalization capabilities. The proposed DeFMO method is trained on a complex synthetic dataset, yet it performs well on real-world data from several datasets. DeFMO outperforms the state of the art and generates high-quality temporal super-resolution frames.