 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Relation Prototype from Unlabeled Texts for Long-tail Relation Extraction
Paper and Code
Nov 27, 2020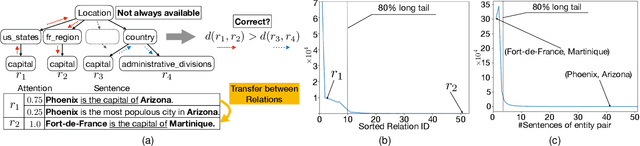
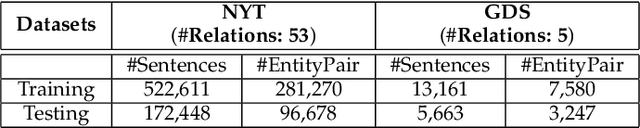
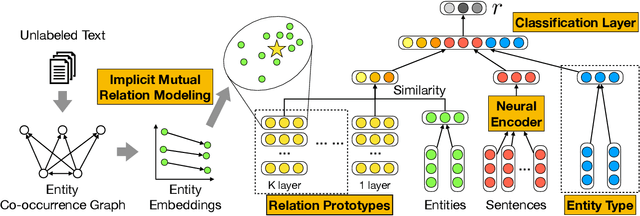
Relation Extraction (RE) is a vital step to complete Knowledge Graph (KG) by extracting entity relations from texts.However, it usually suffers from the long-tail issue. The training data mainly concentrates on a few types of relations, leading to the lackof sufficient annotations for the remaining types of relations. In this paper, we propose a general approach to learn relation prototypesfrom unlabeled texts, to facilitate the long-tail relation extraction by transferring knowledge from the relation types with sufficient trainingdata. We learn relation prototypes as an implicit factor between entities, which reflects the meanings of relations as well as theirproximities for transfer learning. Specifically, we construct a co-occurrence graph from texts, and capture both first-order andsecond-order entity proximities for embedding learning. Based on this, we further optimize the distance from entity pairs tocorresponding prototypes, which can be easily adapted to almost arbitrary RE frameworks. Thus, the learning of infrequent or evenunseen relation types will benefit from semantically proximate relations through pairs of entities and large-scale textual information.We have conducted extensive experiments on two publicly available datasets: New York Times and Google Distant Supervision.Compared with eight state-of-the-art baselines, our proposed model achieves significant improvements (4.1% F1 on average). Furtherresults on long-tail relations demonstrate the effectiveness of the learned relation prototypes. We further conduct an ablation study toinvestigate the impacts of varying components, and apply it to four basic relation extraction models to verify the generalization ability.Finally, we analyze several example cases to give intuitive impressions as qualitative analysis. Our codes will be released later.