 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Pixel-Wise Supervision for Face Anti-Spoofing
Paper and Code
Nov 24, 2020
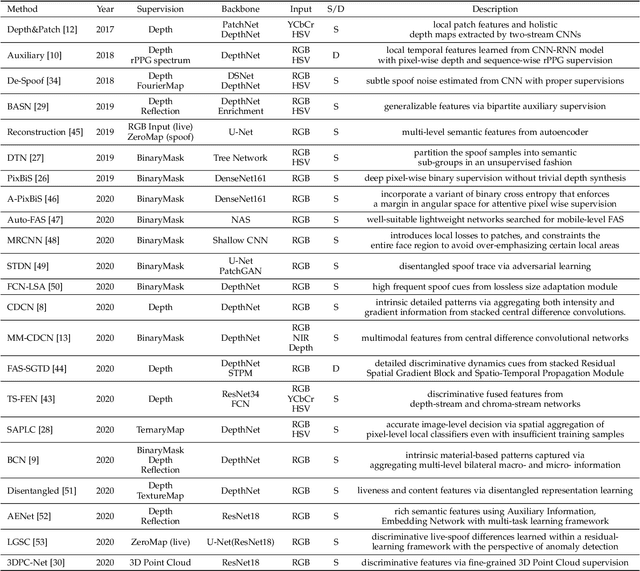
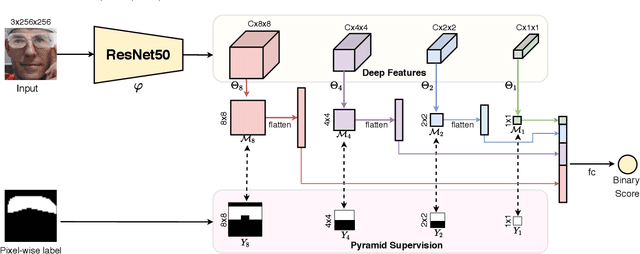
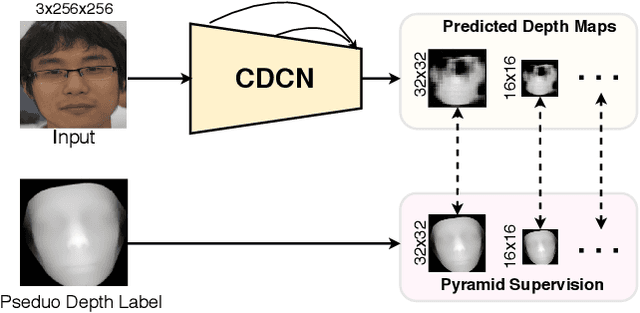
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from the presentation attacks (PAs). As more and more realistic PAs with novel types spring up, it is necessary to develop robust algorithms for detecting unknown attacks even in unseen scenarios. However, deep models supervised by traditional binary loss (e.g., `0' for bonafide vs. `1' for PAs) are weak in describing intrinsic and discriminative spoofing patterns. Recently, pixel-wise supervision has been proposed for the FAS task, intending to provide more fine-grained pixel/patch-level cues. In this paper, we firstly give a comprehensive review and analysis about the existing pixel-wise supervision methods for FAS. Then we propose a novel pyramid supervision, which guides deep models to learn both local details and global semantics from multi-scale spatial context. Extensive experiments are performed on five FAS benchmark datasets to show that, without bells and whistles, the proposed pyramid supervision could not only improve the performance beyond existing pixel-wise supervision frameworks, but also enhance the model's interpretability (i.e., locating the patch-level positions of PAs more reasonably). Furthermore, elaborate studies are conducted for exploring the efficacy of different architecture configurations with two kinds of pixel-wise supervisions (binary mask and depth map supervisions), which provides inspirable insights for future architecture/supervision design.