 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynth2Aug: Cross-domain speaker recognition with TTS synthesized speech
Paper and Code
Nov 24, 2020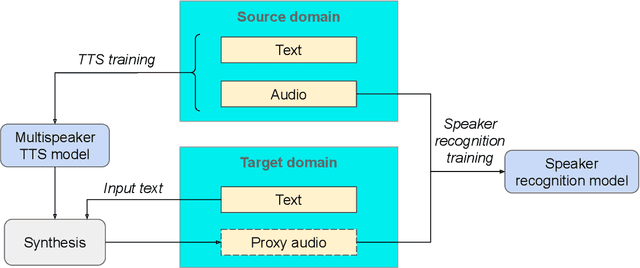
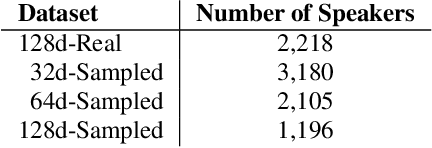
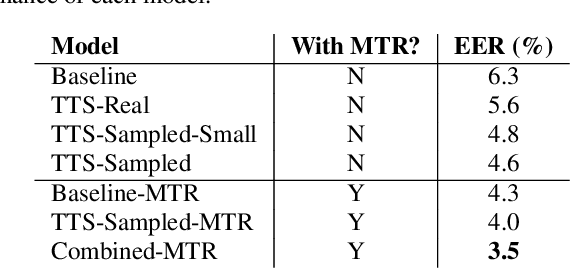
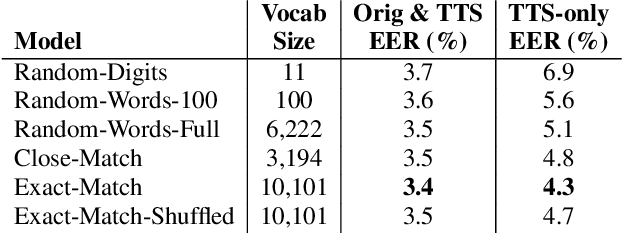
In recent years, Text-To-Speech (TTS) has been used as a data augmentation technique for speech recognition to help complement inadequacies in the training data. Correspondingly, we investigate the use of a multi-speaker TTS system to synthesize speech in support of speaker recognition. In this study we focus the analysis on tasks where a relatively small number of speakers is available for training. We observe on our datasets that TTS synthesized speech improves cross-domain speaker recognition performance and can be combined effectively with multi-style training. Additionally, we explore the effectiveness of different types of text transcripts used for TTS synthesis. Results suggest that matching the textual content of the target domain is a good practice, and if that is not feasible, a transcript with a sufficiently large vocabulary is recommended.