 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKddRES: A Multi-level Knowledge-driven Dialogue Dataset for Restaurant Towards Customized Dialogue System
Paper and Code
Nov 18, 2020

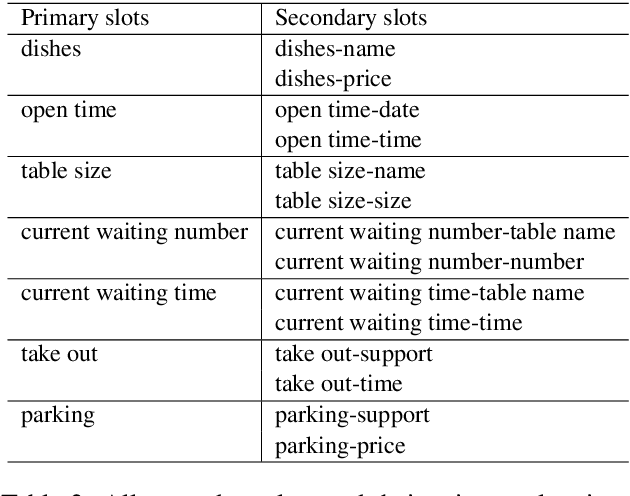
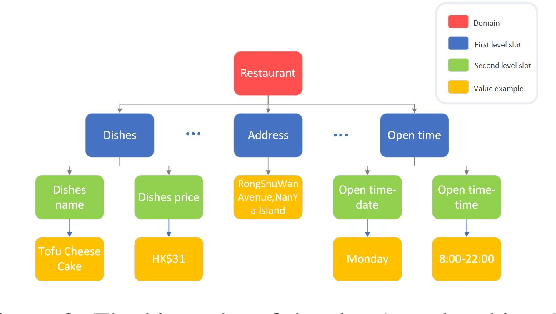
Compared with CrossWOZ (Chinese) and MultiWOZ (English) dataset which have coarse-grained information, there is no dataset which handle fine-grained and hierarchical level information properly. In this paper, we publish a first Cantonese knowledge-driven Dialogue Dataset for REStaurant (KddRES) in Hong Kong, which grounds the information in multi-turn conversations to one specific restaurant. Our corpus contains 0.8k conversations which derive from 10 restaurants with various styles in different regions. In addition to that, we designed fine-grained slots and intents to better capture semantic information. The benchmark experiments and data statistic analysis show the diversity and rich annotations of our dataset. We believe the publish of KddRES can be a necessary supplement of current dialogue datasets and more suitable and valuable for small and middle enterprises (SMEs) of society, such as build a customized dialogue system for each restaurant. The corpus and benchmark models are publicly available.