 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Constrained Dialog Policy Learning via Differentiable Inductive Logic Programming
Paper and Code
Nov 10, 2020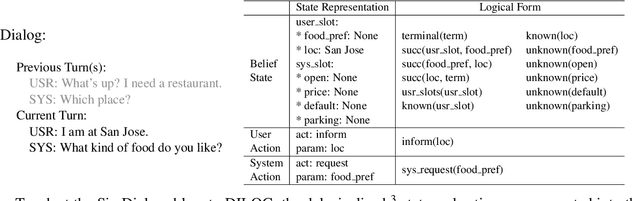
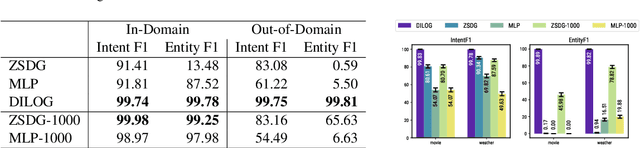

Motivated by the needs of resource constrained dialog policy learning, we introduce dialog policy via differentiable inductive logic (DILOG). We explore the tasks of one-shot learning and zero-shot domain transfer with DILOG on SimDial and MultiWoZ. Using a single representative dialog from the restaurant domain, we train DILOG on the SimDial dataset and obtain 99+% in-domain test accuracy. We also show that the trained DILOG zero-shot transfers to all other domains with 99+% accuracy, proving the suitability of DILOG to slot-filling dialogs. We further extend our study to the MultiWoZ dataset achieving 90+% inform and success metrics. We also observe that these metrics are not capturing some of the shortcomings of DILOG in terms of false positives, prompting us to measure an auxiliary Action F1 score. We show that DILOG is 100x more data efficient than state-of-the-art neural approaches on MultiWoZ while achieving similar performance metrics. We conclude with a discussion on the strengths and weaknesses of DILOG.