Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Strategies, Waveform Model Choice, and Acoustic Configurations for Multi-Speaker End-to-End Speech Synthesis
Paper and Code

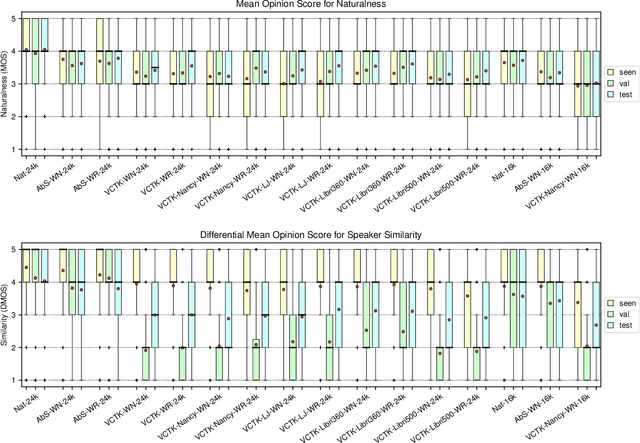
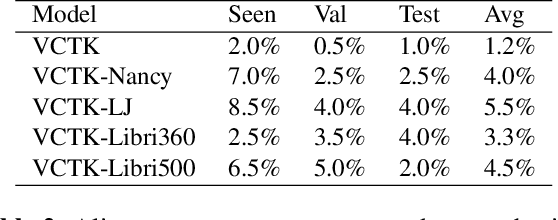
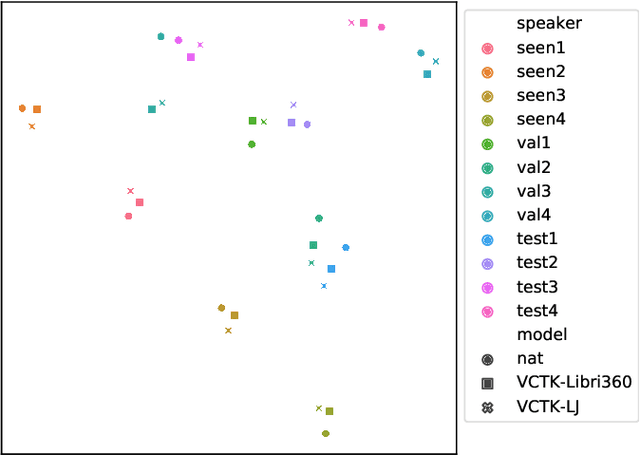
We explore pretraining strategies including choice of base corpus with the aim of choosing the best strategy for zero-shot multi-speaker end-to-end synthesis. We also examine choice of neural vocoder for waveform synthesis, as well as acoustic configurations used for mel spectrograms and final audio output. We find that fine-tuning a multi-speaker model from found audiobook data that has passed a simple quality threshold can improve naturalness and similarity to unseen target speakers of synthetic speech. Additionally, we find that listeners can discern between a 16kHz and 24kHz sampling rate, and that WaveRNN produces output waveforms of a comparable quality to WaveNet, with a faster inference time.
* Technical report
View paper on