 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Cross-modal Proxy Hashing
Paper and Code
Nov 06, 2020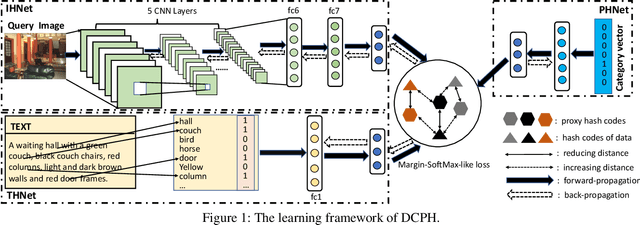
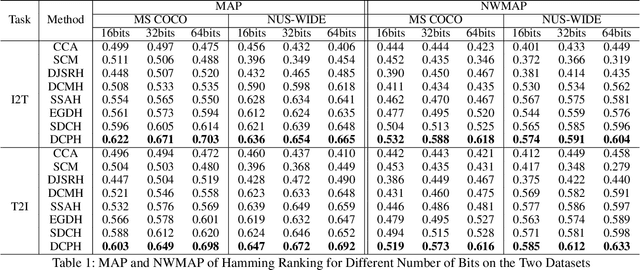
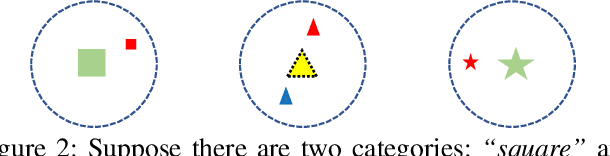
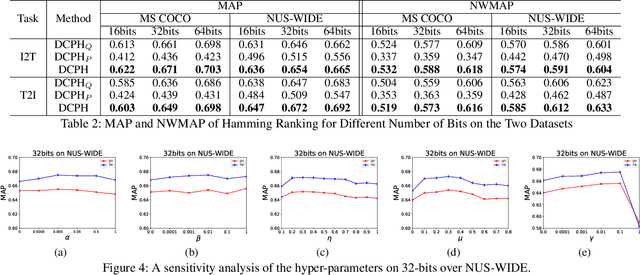
Due to their high retrieval efficiency and low storage cost for cross-modal search task, cross-modal hashing methods have attracted considerable attention. For supervised cross-modal hashing methods, how to make the learned hash codes preserve semantic structure information sufficiently is a key point to further enhance the retrieval performance. As far as we know, almost all supervised cross-modal hashing methods preserve semantic structure information depending on at-least-one similarity definition fully or partly, i.e., it defines two datapoints as similar ones if they share at least one common category otherwise they are dissimilar. Obviously, the at-least-one similarity misses abundant semantic structure information. To tackle this problem, in this paper, we propose a novel Deep Cross-modal Proxy Hashing, called DCPH. Specifically, DCPH first learns a proxy hashing network to generate a discriminative proxy hash code for each category. Then, by utilizing the learned proxy hash code as supervised information, a novel $Margin$-$SoftMax$-$like\ loss$ is proposed without defining the at-least-one similarity between datapoints. By minimizing the novel $Margin$-$SoftMax$-$like\ loss$, the learned hash codes will simultaneously preserve the cross-modal similarity and abundant semantic structure information well. Extensive experiments on two benchmark datasets show that the proposed method outperforms the state-of-the-art baselines in cross-modal retrieval task.