 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pattern Discovery from Thematic Speech Archives Based on Multilingual Bottleneck Features
Paper and Code
Nov 03, 2020
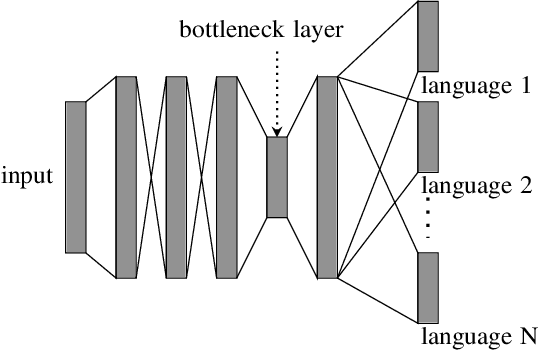
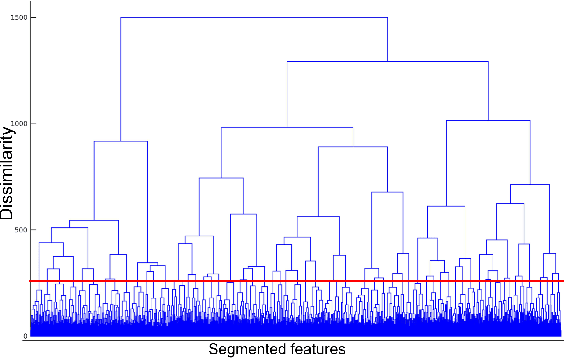
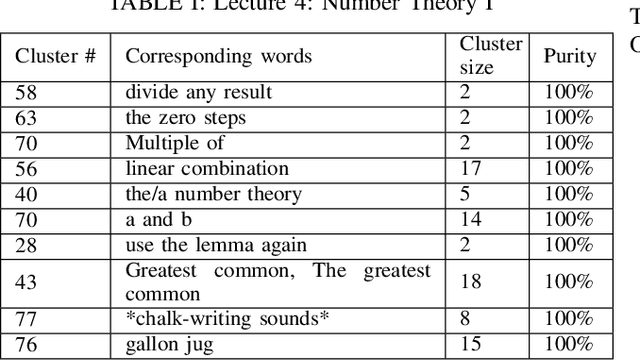
The present study tackles the problem of automatically discovering spoken keywords from untranscribed audio archives without requiring word-by-word speech transcription by automatic speech recognition (ASR) technology. The problem is of practical significance in many applications of speech analytics, including those concerning low-resource languages, and large amount of multilingual and multi-genre data. We propose a two-stage approach, which comprises unsupervised acoustic modeling and decoding, followed by pattern mining in acoustic unit sequences. The whole process starts by deriving and modeling a set of subword-level speech units with untranscribed data. With the unsupervisedly trained acoustic models, a given audio archive is represented by a pseudo transcription, from which spoken keywords can be discovered by string mining algorithms. For unsupervised acoustic modeling, a deep neural network trained by multilingual speech corpora is used to generate speech segmentation and compute bottleneck features for segment clustering. Experimental results show that the proposed system is able to effectively extract topic-related words and phrases from the lecture recordings on MIT OpenCourseWare.