 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss-rescaling VQA: Revisiting Language Prior Problem from a Class-imbalance View
Paper and Code
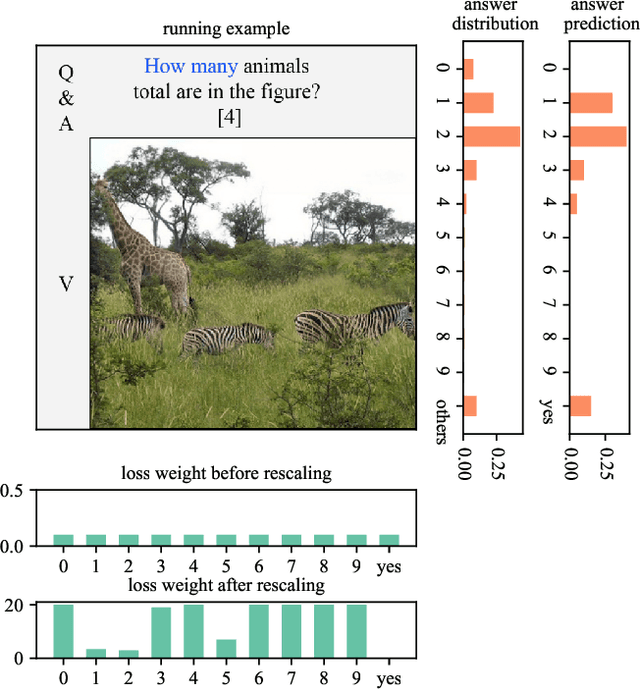
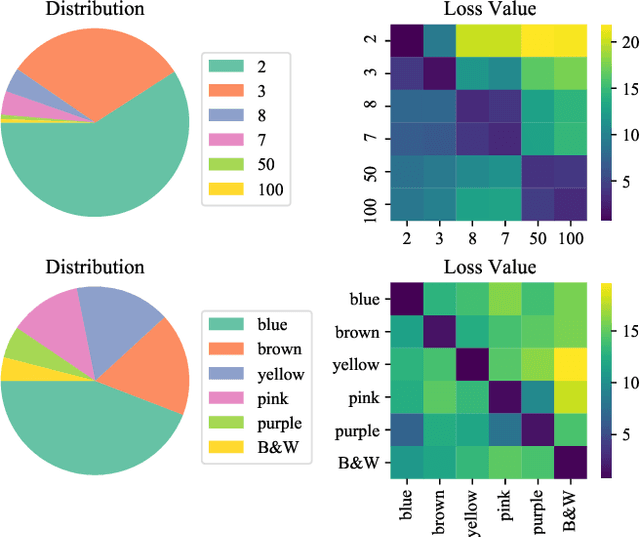
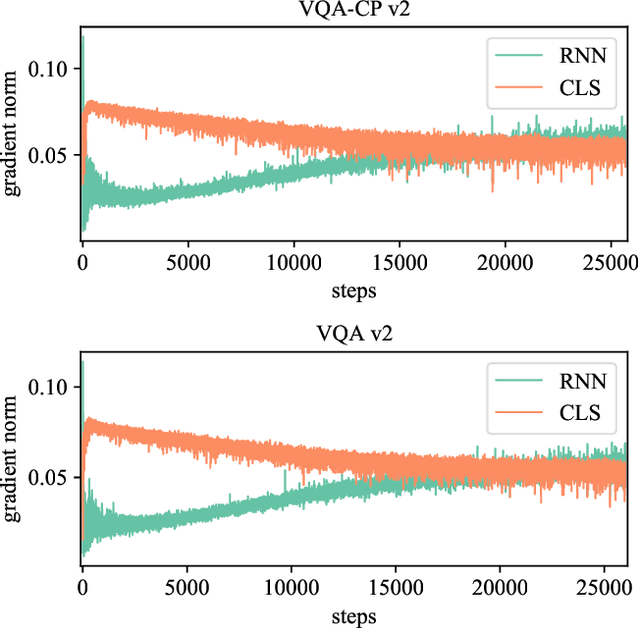
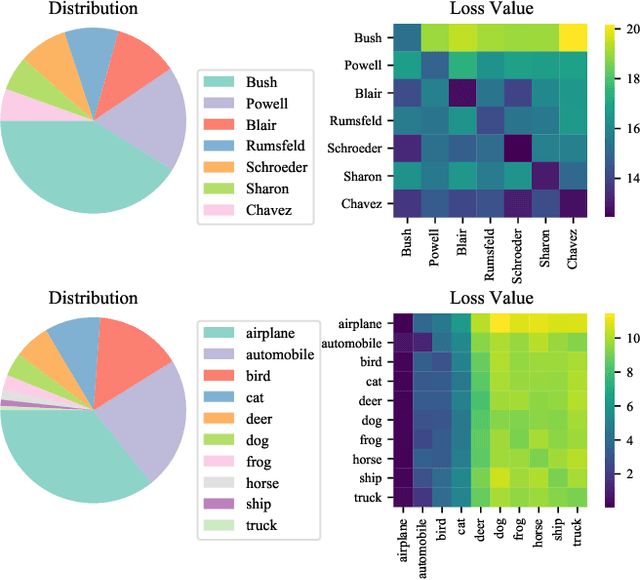
Recent studies have pointed out that many well-developed Visual Question Answering (VQA) models are heavily affected by the language prior problem, which refers to making predictions based on the co-occurrence pattern between textual questions and answers instead of reasoning visual contents. To tackle it, most existing methods focus on enhancing visual feature learning to reduce this superficial textual shortcut influence on VQA model decisions. However, limited effort has been devoted to providing an explicit interpretation for its inherent cause. It thus lacks a good guidance for the research community to move forward in a purposeful way, resulting in model construction perplexity in overcoming this non-trivial problem. In this paper, we propose to interpret the language prior problem in VQA from a class-imbalance view. Concretely, we design a novel interpretation scheme whereby the loss of mis-predicted frequent and sparse answers of the same question type is distinctly exhibited during the late training phase. It explicitly reveals why the VQA model tends to produce a frequent yet obviously wrong answer, to a given question whose right answer is sparse in the training set. Based upon this observation, we further develop a novel loss re-scaling approach to assign different weights to each answer based on the training data statistics for computing the final loss. We apply our approach into three baselines and the experimental results on two VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify the validity of the class imbalance interpretation scheme on other computer vision tasks, such as face recognition and image classification.