 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Networks from the Principle of Rate Reduction
Paper and Code
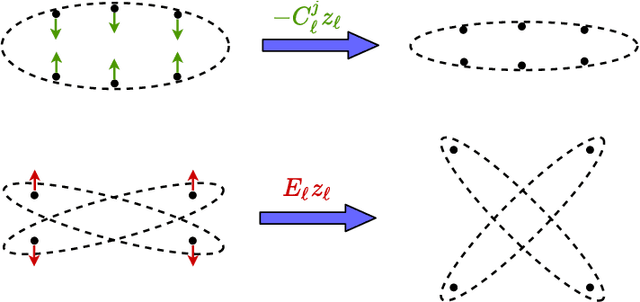
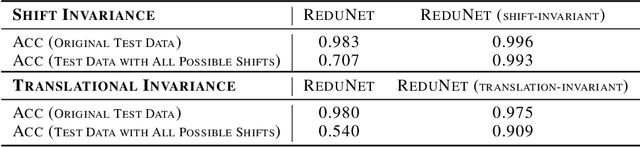
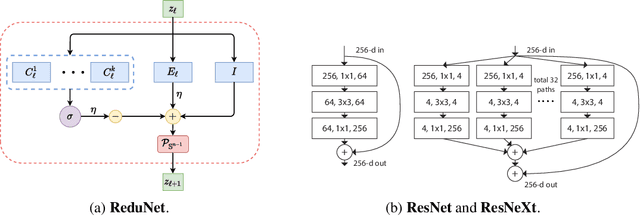

This work attempts to interpret modern deep (convolutional) networks from the principles of rate reduction and (shift) invariant classification. We show that the basic iterative gradient ascent scheme for optimizing the rate reduction of learned features naturally leads to a multi-layer deep network, one iteration per layer. The layered architectures, linear and nonlinear operators, and even parameters of the network are all explicitly constructed layer-by-layer in a forward propagation fashion by emulating the gradient scheme. All components of this "white box" network have precise optimization, statistical, and geometric interpretation. This principled framework also reveals and justifies the role of multi-channel lifting and sparse coding in early stage of deep networks. Moreover, all linear operators of the so-derived network naturally become multi-channel convolutions when we enforce classification to be rigorously shift-invariant. The derivation also indicates that such a convolutional network is significantly more efficient to construct and learn in the spectral domain. Our preliminary simulations and experiments indicate that so constructed deep network can already learn a good discriminative representation even without any back propagation training.