 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Limited Labeled Dialogue State Tracking with Self-Supervision
Paper and Code

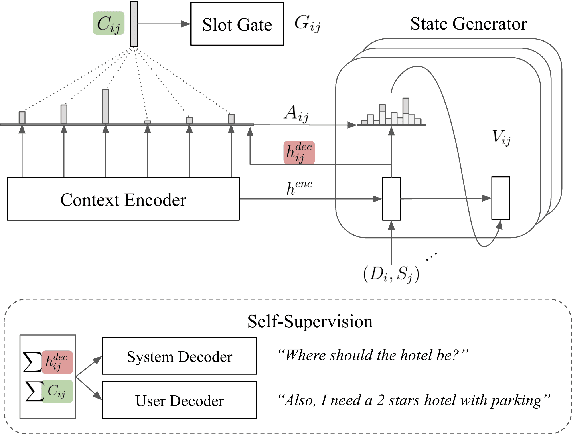
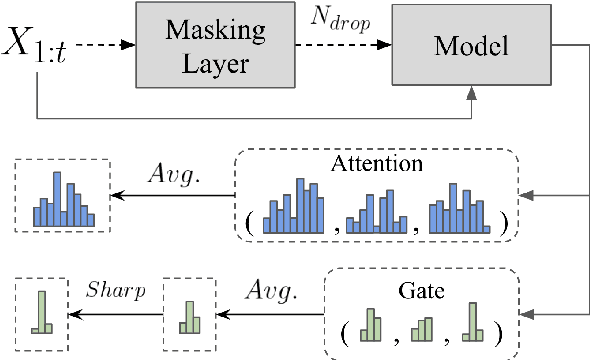
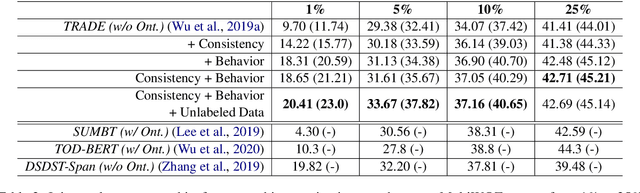
Existing dialogue state tracking (DST) models require plenty of labeled data. However, collecting high-quality labels is costly, especially when the number of domains increases. In this paper, we address a practical DST problem that is rarely discussed, i.e., learning efficiently with limited labeled data. We present and investigate two self-supervised objectives: preserving latent consistency and modeling conversational behavior. We encourage a DST model to have consistent latent distributions given a perturbed input, making it more robust to an unseen scenario. We also add an auxiliary utterance generation task, modeling a potential correlation between conversational behavior and dialogue states. The experimental results show that our proposed self-supervised signals can improve joint goal accuracy by 8.95\% when only 1\% labeled data is used on the MultiWOZ dataset. We can achieve an additional 1.76\% improvement if some unlabeled data is jointly trained as semi-supervised learning. We analyze and visualize how our proposed self-supervised signals help the DST task and hope to stimulate future data-efficient DST research.