 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Verifiable Information Embedding Attacks to Deep Neural Networks via Error-Correcting Codes
Paper and Code
Oct 26, 2020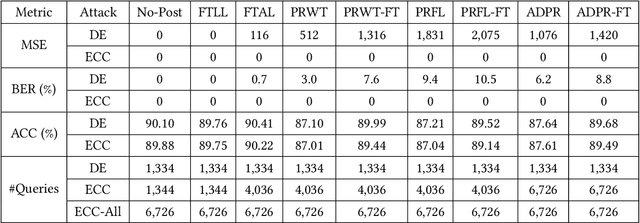
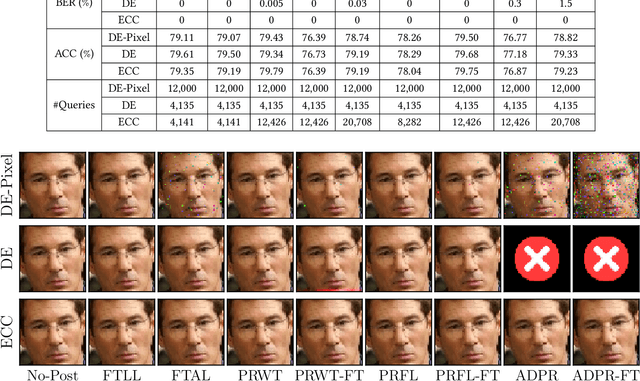
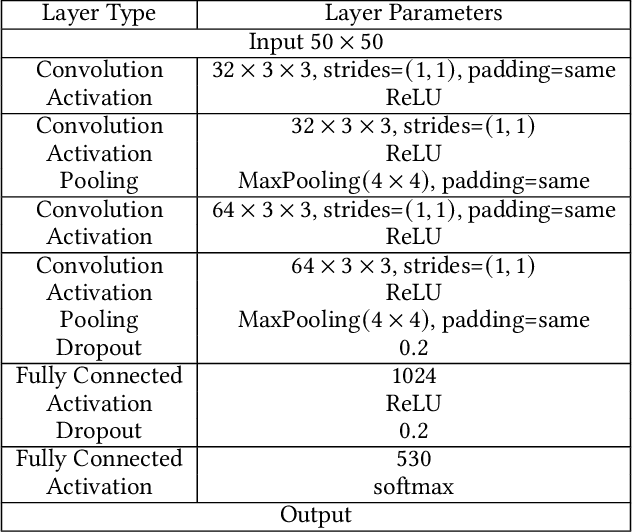
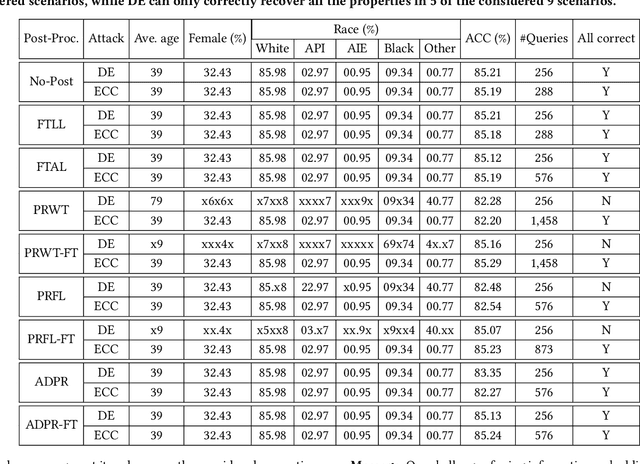
In the era of deep learning, a user often leverages a third-party machine learning tool to train a deep neural network (DNN) classifier and then deploys the classifier as an end-user software product or a cloud service. In an information embedding attack, an attacker is the provider of a malicious third-party machine learning tool. The attacker embeds a message into the DNN classifier during training and recovers the message via querying the API of the black-box classifier after the user deploys it. Information embedding attacks have attracted growing attention because of various applications such as watermarking DNN classifiers and compromising user privacy. State-of-the-art information embedding attacks have two key limitations: 1) they cannot verify the correctness of the recovered message, and 2) they are not robust against post-processing of the classifier. In this work, we aim to design information embedding attacks that are verifiable and robust against popular post-processing methods. Specifically, we leverage Cyclic Redundancy Check to verify the correctness of the recovered message. Moreover, to be robust against post-processing, we leverage Turbo codes, a type of error-correcting codes, to encode the message before embedding it to the DNN classifier. We propose to recover the message via adaptively querying the classifier to save queries. Our adaptive recovery strategy leverages the property of Turbo codes that supports error correcting with a partial code. We evaluate our information embedding attacks using simulated messages and apply them to three applications, where messages have semantic interpretations. We consider 8 popular methods to post-process the classifier. Our results show that our attacks can accurately and verifiably recover the messages in all considered scenarios, while state-of-the-art attacks cannot accurately recover the messages in many scenarios.