 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose
Paper and Code
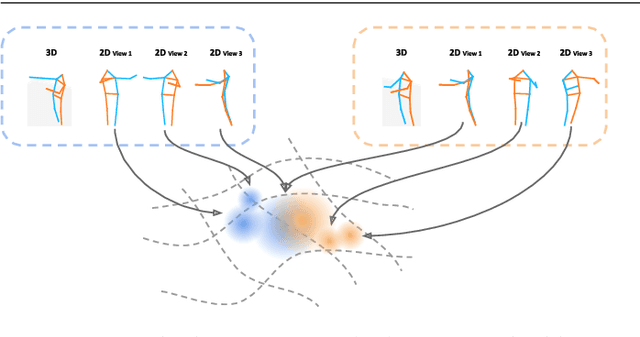
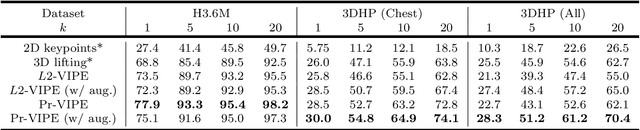
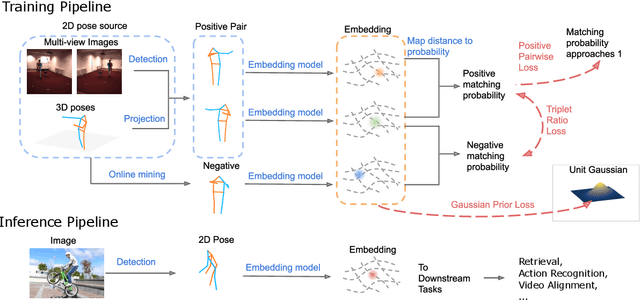

Recognition of human poses and activities is crucial for autonomous systems to interact smoothly with people. However, cameras generally capture human poses in 2D as images and videos, which can have significant appearance variations across viewpoints. To address this, we explore recognizing similarity in 3D human body poses from 2D information, which has not been well-studied in existing works. Here, we propose an approach to learning a compact view-invariant embedding space from 2D body joint keypoints, without explicitly predicting 3D poses. Input ambiguities of 2D poses from projection and occlusion are difficult to represent through a deterministic mapping, and therefore we use probabilistic embeddings. In order to enable our embeddings to work with partially visible input keypoints, we further investigate different keypoint occlusion augmentation strategies during training. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 3D pose estimation models. We further show that keypoint occlusion augmentation during training significantly improves retrieval performance on partial 2D input poses. Results on action recognition and video alignment demonstrate that our embeddings, without any additional training, achieves competitive performance relative to other models specifically trained for each task.