 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Universal Dependency Parsing in the Age of the Transformer: What Works, and What Doesn't
Paper and Code

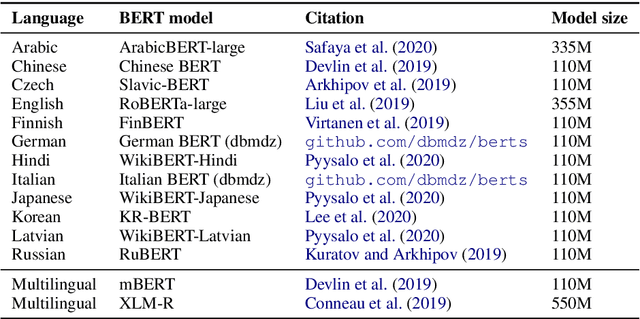
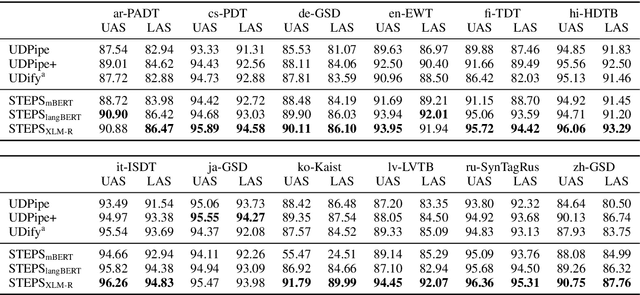
Current state-of-the-art graph-based dependency parsers differ on various dimensions. Among others, these include (a) the choice of pre-trained word embeddings or language models used for representing token, (b) training setups performing only parsing or additional tasks such as part-of-speech-tagging, and (c) their mechanism of constructing trees or graphs from edge scores. Because of this, it is difficult to estimate the impact of these architectural decisions when comparing parsers. In this paper, we perform a series of experiments on STEPS, a new modular graph-based parser for basic and enhanced Universal Dependencies, analyzing the effects of architectural configurations. We find that pre-trained embeddings have by far the greatest and most clear-cut impact on parser performance. The choice of factorized vs. unfactorized architectures and a multi-task training setup affect parsing accuracy in more subtle ways, depending on target language and output representation (trees vs. graphs). Our parser achieves new state-of-the-art results for a wide range of languages on both basic as well as enhanced Universal Dependencies, using a unified and comparatively simple architecture for both parsing tasks.