 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Precision Embedding Using a Cache
Paper and Code
Oct 23, 2020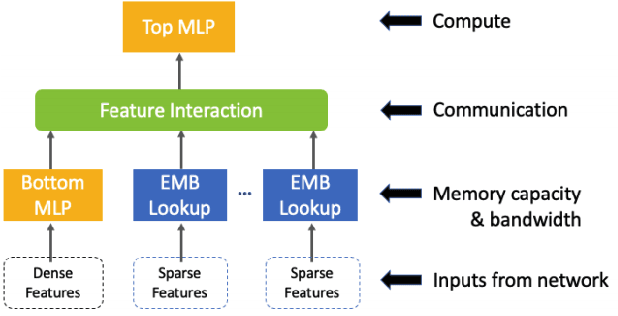

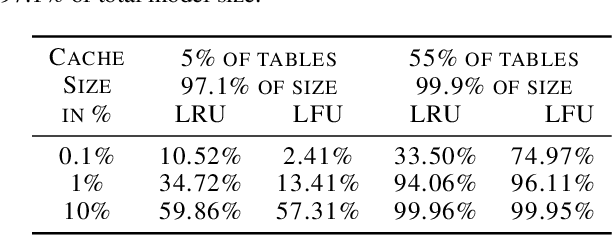
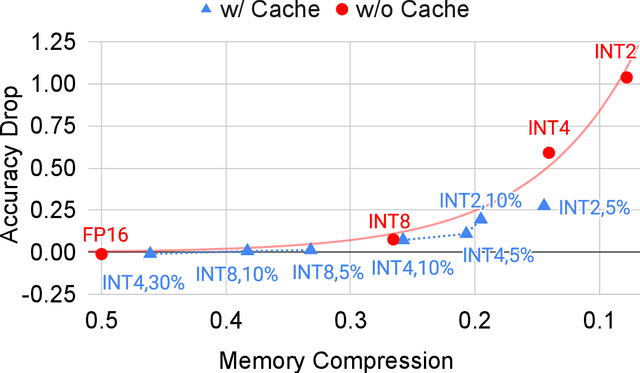
In recommendation systems, practitioners observed that increase in the number of embedding tables and their sizes often leads to significant improvement in model performances. Given this and the business importance of these models to major internet companies, embedding tables for personalization tasks have grown to terabyte scale and continue to grow at a significant rate. Meanwhile, these large-scale models are often trained with GPUs where high-performance memory is a scarce resource, thus motivating numerous work on embedding table compression during training. We propose a novel change to embedding tables using a cache memory architecture, where the majority of rows in an embedding is trained in low precision, and the most frequently or recently accessed rows cached and trained in full precision. The proposed architectural change works in conjunction with standard precision reduction and computer arithmetic techniques such as quantization and stochastic rounding. For an open source deep learning recommendation model (DLRM) running with Criteo-Kaggle dataset, we achieve 3x memory reduction with INT8 precision embedding tables and full-precision cache whose size are 5% of the embedding tables, while maintaining accuracy. For an industrial scale model and dataset, we achieve even higher >7x memory reduction with INT4 precision and cache size 1% of embedding tables, while maintaining accuracy, and 16% end-to-end training speedup by reducing GPU-to-host data transfers.