 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTBNN: Rethinking Non-linearity for 1-bit CNNs and Going Beyond
Paper and Code
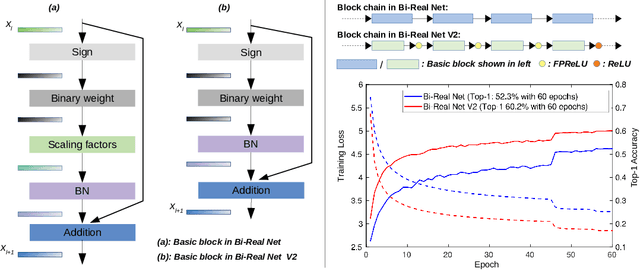


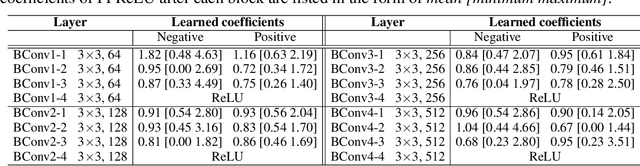
Binary neural networks (BNNs), where both weights and activations are binarized into 1 bit, have been widely studied in recent years due to its great benefit of highly accelerated computation and substantially reduced memory footprint that appeal to the development of resource constrained devices. In contrast to previous methods tending to reduce the quantization error for training BNN structures, we argue that the binarized convolution process owns an increasing linearity towards the target of minimizing such error, which in turn hampers BNN's discriminative ability. In this paper, we re-investigate and tune proper non-linear modules to fix that contradiction, leading to a strong baseline which achieves state-of-the-art performance on the large-scale ImageNet dataset in terms of accuracy and training efficiency. To go further, we find that the proposed BNN model still has much potential to be compressed by making a better use of the efficient binary operations, without losing accuracy. In addition, the limited capacity of the BNN model can also be increased with the help of group execution. Based on these insights, we are able to improve the baseline with an additional 4~5% top-1 accuracy gain even with less computational cost. Our code will be made public at https://github.com/zhuogege1943/ftbnn.