 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciSummPip: An Unsupervised Scientific Paper Summarization Pipeline
Paper and Code
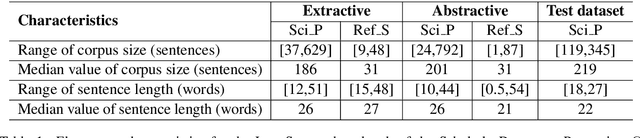
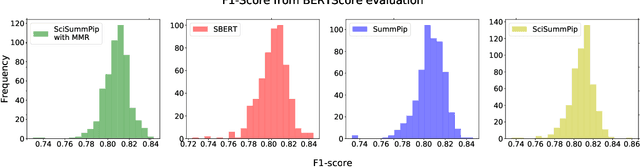
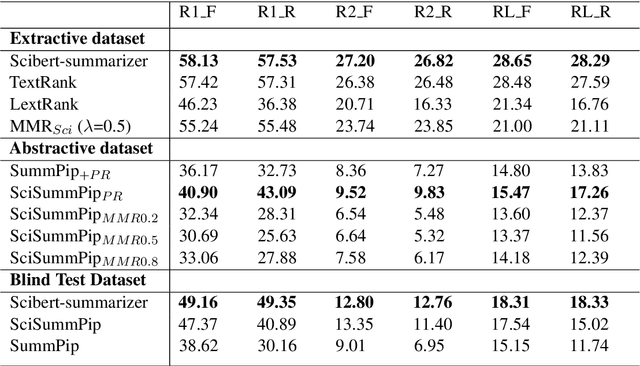

The Scholarly Document Processing (SDP) workshop is to encourage more efforts on natural language understanding of scientific task. It contains three shared tasks and we participate in the LongSumm shared task. In this paper, we describe our text summarization system, SciSummPip, inspired by SummPip (Zhao et al., 2020) that is an unsupervised text summarization system for multi-document in news domain. Our SciSummPip includes a transformer-based language model SciBERT (Beltagy et al., 2019) for contextual sentence representation, content selection with PageRank (Page et al., 1999), sentence graph construction with both deep and linguistic information, sentence graph clustering and within-graph summary generation. Our work differs from previous method in that content selection and a summary length constraint is applied to adapt to the scientific domain. The experiment results on both training dataset and blind test dataset show the effectiveness of our method, and we empirically verify the robustness of modules used in SciSummPip with BERTScore (Zhang et al., 2019a).