 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Layer-Wise Learning is Hard to Scale-up and a Possible Solution via Accelerated Downsampling
Paper and Code
Oct 15, 2020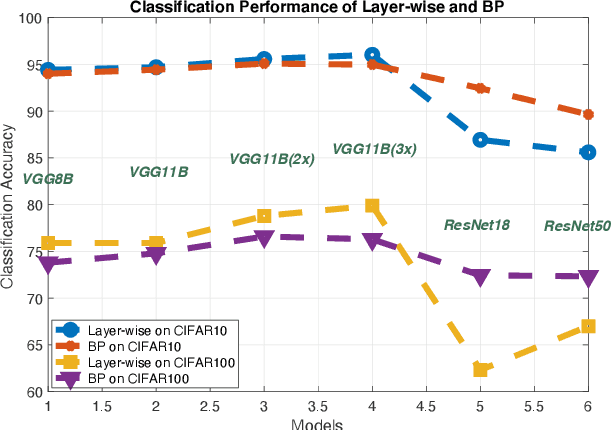
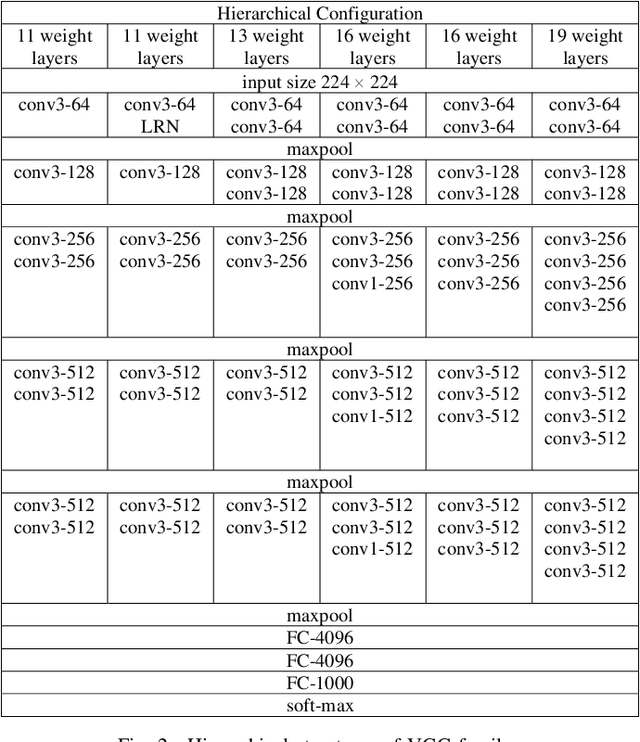
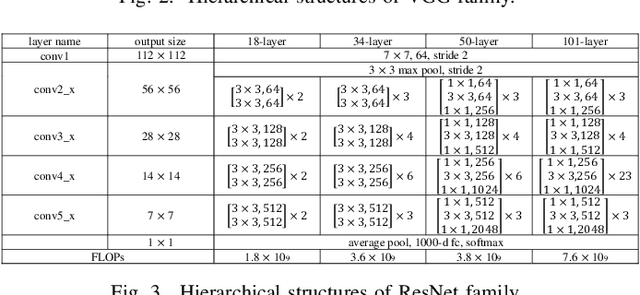
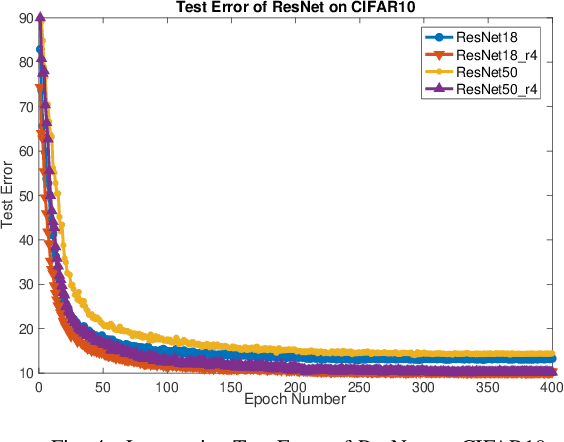
Layer-wise learning, as an alternative to global back-propagation, is easy to interpret, analyze, and it is memory efficient. Recent studies demonstrate that layer-wise learning can achieve state-of-the-art performance in image classification on various datasets. However, previous studies of layer-wise learning are limited to networks with simple hierarchical structures, and the performance decreases severely for deeper networks like ResNet. This paper, for the first time, reveals the fundamental reason that impedes the scale-up of layer-wise learning is due to the relatively poor separability of the feature space in shallow layers. This argument is empirically verified by controlling the intensity of the convolution operation in local layers. We discover that the poorly-separable features from shallow layers are mismatched with the strong supervision constraint throughout the entire network, making the layer-wise learning sensitive to network depth. The paper further proposes a downsampling acceleration approach to weaken the poor learning of shallow layers so as to transfer the learning emphasis to deep feature space where the separability matches better with the supervision restraint. Extensive experiments have been conducted to verify the new finding and demonstrate the advantages of the proposed downsampling acceleration in improving the performance of layer-wise learning.