 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Engineering Imperceptible Backdoor Attacks on Deep Neural Networks for Detection and Training Set Cleansing
Paper and Code
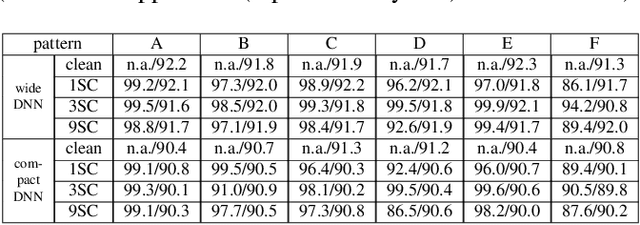
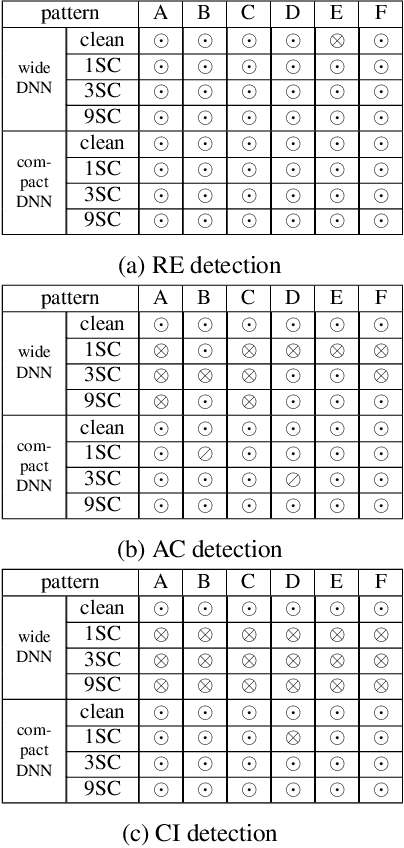

Backdoor data poisoning is an emerging form of adversarial attack usually against deep neural network image classifiers. The attacker poisons the training set with a relatively small set of images from one (or several) source class(es), embedded with a backdoor pattern and labeled to a target class. For a successful attack, during operation, the trained classifier will: 1) misclassify a test image from the source class(es) to the target class whenever the same backdoor pattern is present; 2) maintain a high classification accuracy for backdoor-free test images. In this paper, we make a break-through in defending backdoor attacks with imperceptible backdoor patterns (e.g. watermarks) before/during the training phase. This is a challenging problem because it is a priori unknown which subset (if any) of the training set has been poisoned. We propose an optimization-based reverse-engineering defense, that jointly: 1) detects whether the training set is poisoned; 2) if so, identifies the target class and the training images with the backdoor pattern embedded; and 3) additionally, reversely engineers an estimate of the backdoor pattern used by the attacker. In benchmark experiments on CIFAR-10, for a large variety of attacks, our defense achieves a new state-of-the-art by reducing the attack success rate to no more than 4.9% after removing detected suspicious training images.