 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Future: Cycle Encoding Prediction for Self-supervised Contrastive Video Representation Learning
Paper and Code
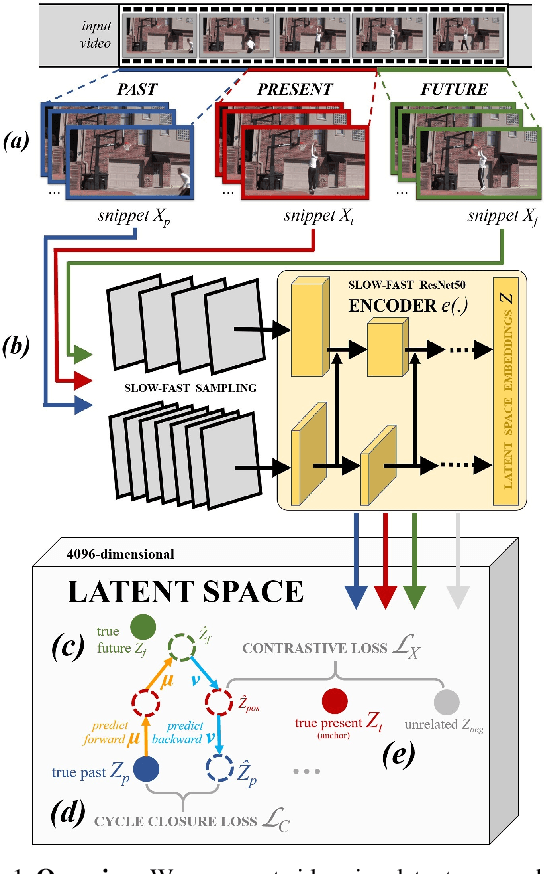
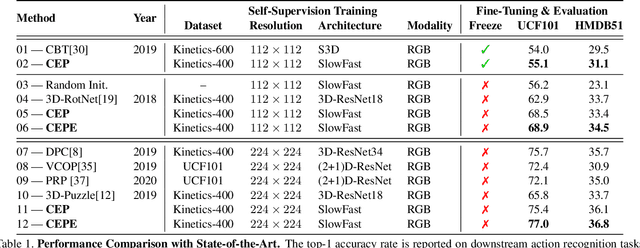

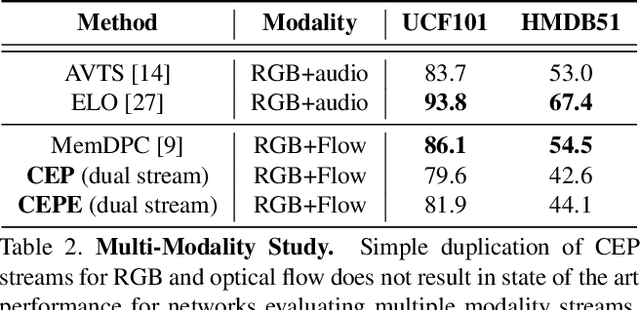
In this paper we show that learning video feature spaces in which temporal cycles are maximally predictable benefits action classification. In particular, we propose a novel learning approach termed Cycle Encoding Prediction (CEP) that is able to effectively represent high-level spatio-temporal structure of unlabelled video content. CEP builds a latent space wherein the concept of closed forward-backward as well as backward-forward temporal loops is approximately preserved. As a self-supervision signal, CEP leverages the bi-directional temporal coherence of the video stream and applies loss functions that encourage both temporal cycle closure as well as contrastive feature separation. Architecturally, the underpinning network structure utilises a single feature encoder for all video snippets, adding two predictive modules that learn temporal forward and backward transitions. We apply our framework for pretext training of networks for action recognition tasks. We report significantly improved results for the standard datasets UCF101 and HMDB51. Detailed ablation studies support the effectiveness of the proposed components. We publish source code for the CEP components in full with this paper.