 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Self-supervised Pre-training via a Fully-Explored Masked Language Model
Paper and Code
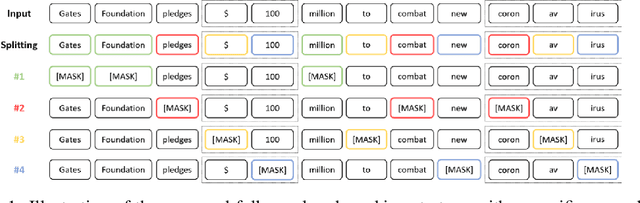
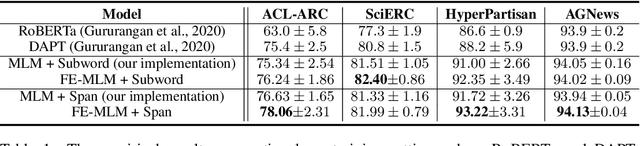
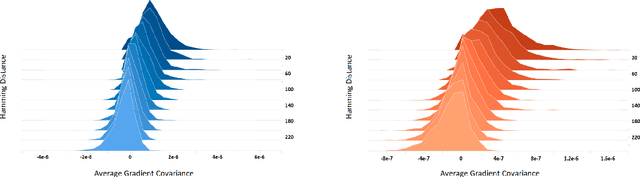

Masked Language Model (MLM) framework has been widely adopted for self-supervised language pre-training. In this paper, we argue that randomly sampled masks in MLM would lead to undesirably large gradient variance. Thus, we theoretically quantify the gradient variance via correlating the gradient covariance with the Hamming distance between two different masks (given a certain text sequence). To reduce the variance due to the sampling of masks, we propose a fully-explored masking strategy, where a text sequence is divided into a certain number of non-overlapping segments. Thereafter, the tokens within one segment are masked for training. We prove, from a theoretical perspective, that the gradients derived from this new masking schema have a smaller variance and can lead to more efficient self-supervised training. We conduct extensive experiments on both continual pre-training and general pre-training from scratch. Empirical results confirm that this new masking strategy can consistently outperform standard random masking. Detailed efficiency analysis and ablation studies further validate the advantages of our fully-explored masking strategy under the MLM framework.