 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-sourced Dataset Protection via Backdoor Watermarking
Paper and Code



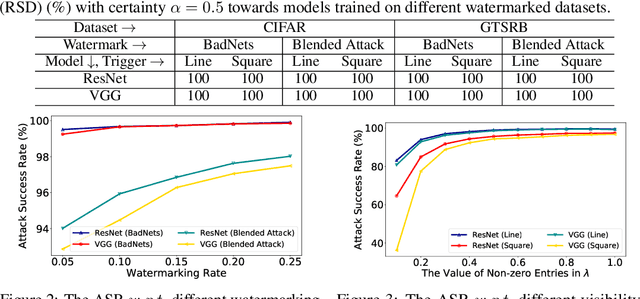
The rapid development of deep learning has benefited from the release of some high-quality open-sourced datasets ($e.g.$, ImageNet), which allows researchers to easily verify the effectiveness of their algorithms. Almost all existing open-sourced datasets require that they can only be adopted for academic or educational purposes rather than commercial purposes, whereas there is still no good way to protect them. In this paper, we propose a backdoor embedding based dataset watermarking method to protect an open-sourced image-classification dataset by verifying whether it is used for training a third-party model. Specifically, the proposed method contains two main processes, including dataset watermarking and dataset verification. We adopt classical poisoning-based backdoor attacks ($e.g.$, BadNets) for dataset watermarking, $i.e.$, generating some poisoned samples by adding a certain trigger ($e.g.$, a local patch) onto some benign samples, labeled with a pre-defined target class. Based on the proposed backdoor-based watermarking, we use a hypothesis test guided method for dataset verification based on the posterior probability generated by the suspicious third-party model of the benign samples and their correspondingly watermarked samples ($i.e.$, images with trigger) on the target class. Experiments on some benchmark datasets are conducted, which verify the effectiveness of the proposed method.