Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Language Model Based Active Learning for Sentence Matching
Paper and Code
Oct 12, 2020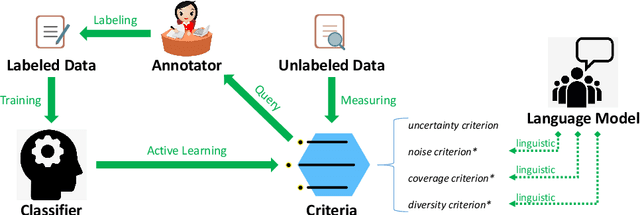
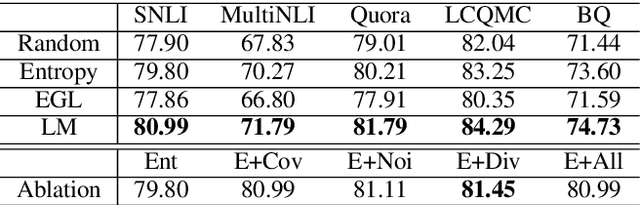
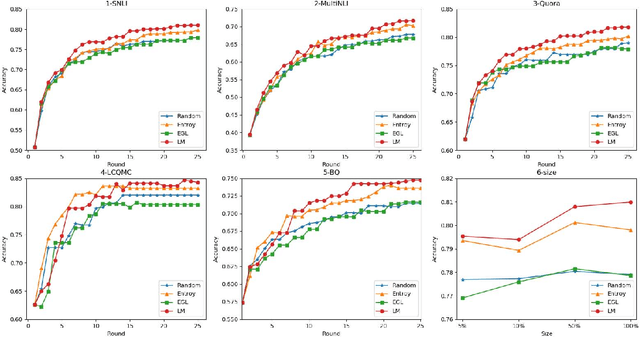
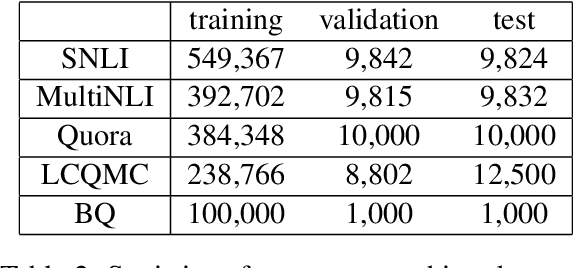
Active learning is able to significantly reduce the annotation cost for data-driven techniques. However, previous active learning approaches for natural language processing mainly depend on the entropy-based uncertainty criterion, and ignore the characteristics of natural language. In this paper, we propose a pre-trained language model based active learning approach for sentence matching. Differing from previous active learning, it can provide linguistic criteria to measure instances and help select more efficient instances for annotation. Experiments demonstrate our approach can achieve greater accuracy with fewer labeled training instances.
* Accepted by the conference of coling 2020
View paper on