 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCo Pretraining Improves Representation and Transferability of Chest X-ray Models
Paper and Code


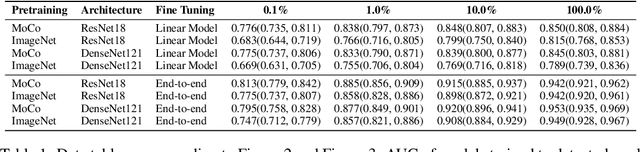
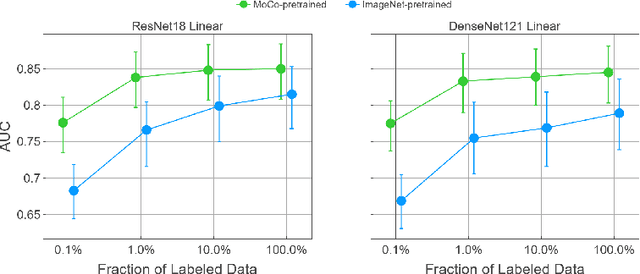
Self-supervised approaches such as Momentum Contrast (MoCo) can leverage unlabeled data to produce pretrained models for subsequent fine-tuning on labeled data. While MoCo has demonstrated promising results on natural image classification tasks, its application to medical imaging tasks like chest X-ray interpretation has been limited. Chest X-ray interpretation is fundamentally different from natural image classification in ways that may limit the applicability of self-supervised approaches. In this work, we investigate whether MoCo-pretraining leads to better representations or initializations for chest X-ray interpretation. We conduct MoCo-pretraining on CheXpert, a large labeled dataset of X-rays, followed by supervised fine-tuning experiments on the pleural effusion task. Using 0.1% of labeled training data, we find that a linear model trained on MoCo-pretrained representations outperforms one trained on representations without MoCo-pretraining by an AUC of 0.096 (95% CI 0.061, 0.130), indicating that MoCo-pretrained representations are of higher quality. Furthermore, a model fine-tuned end-to-end with MoCo-pretraining outperforms its non-MoCo-pretrained counterpart by an AUC of 0.037 (95% CI 0.015, 0.062) with the 0.1% label fraction. These AUC improvements are observed for all label fractions for both the linear model and an end-to-end fine-tuned model with the greater improvements for smaller label fractions. Finally, we observe similar results on a small, target chest X-ray dataset (Shenzhen dataset for tuberculosis) with MoCo-pretraining done on the source dataset (CheXpert), which suggests that pretraining on unlabeled X-rays can provide transfer learning benefits for a target task. Our study demonstrates that MoCo-pretraining provides high-quality representations and transferable initializations for chest X-ray interpretation.