 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Continuous Sign Language Recognition via Cross Modality Augmentation
Paper and Code
Oct 11, 2020
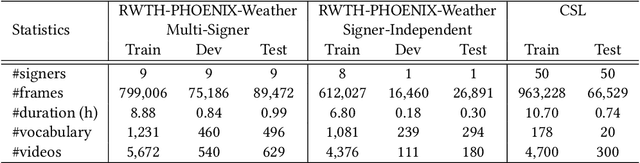

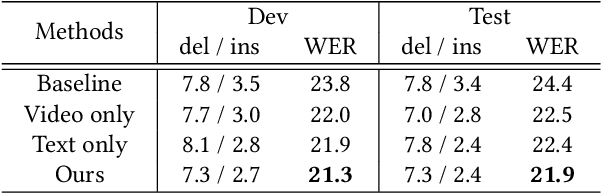
Continuous sign language recognition (SLR) deals with unaligned video-text pair and uses the word error rate (WER), i.e., edit distance, as the main evaluation metric. Since it is not differentiable, we usually instead optimize the learning model with the connectionist temporal classification (CTC) objective loss, which maximizes the posterior probability over the sequential alignment. Due to the optimization gap, the predicted sentence with the highest decoding probability may not be the best choice under the WER metric. To tackle this issue, we propose a novel architecture with cross modality augmentation. Specifically, we first augment cross-modal data by simulating the calculation procedure of WER, i.e., substitution, deletion and insertion on both text label and its corresponding video. With these real and generated pseudo video-text pairs, we propose multiple loss terms to minimize the cross modality distance between the video and ground truth label, and make the network distinguish the difference between real and pseudo modalities. The proposed framework can be easily extended to other existing CTC based continuous SLR architectures. Extensive experiments on two continuous SLR benchmarks, i.e., RWTH-PHOENIX-Weather and CSL, validate the effectiveness of our proposed method.