 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIND: Human-in-the-Loop Debugging Deep Text Classifiers
Paper and Code
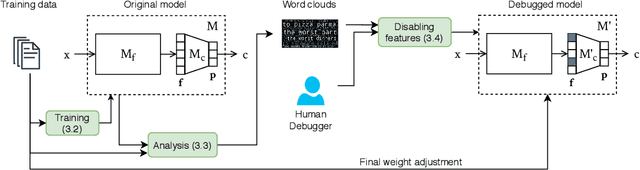
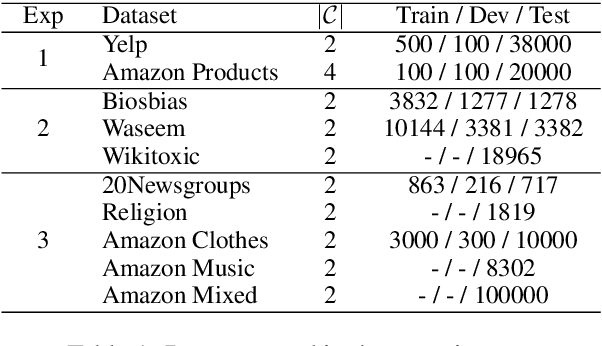
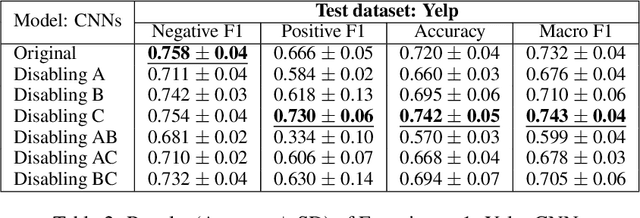
Since obtaining a perfect training dataset (i.e., a dataset which is considerably large, unbiased, and well-representative of unseen cases) is hardly possible, many real-world text classifiers are trained on the available, yet imperfect, datasets. These classifiers are thus likely to have undesirable properties. For instance, they may have biases against some sub-populations or may not work effectively in the wild due to overfitting. In this paper, we propose FIND -- a framework which enables humans to debug deep learning text classifiers by disabling irrelevant hidden features. Experiments show that by using FIND, humans can improve CNN text classifiers which were trained under different types of imperfect datasets (including datasets with biases and datasets with dissimilar train-test distributions).