 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate, Efficient and Scalable Training of Graph Neural Networks
Paper and Code
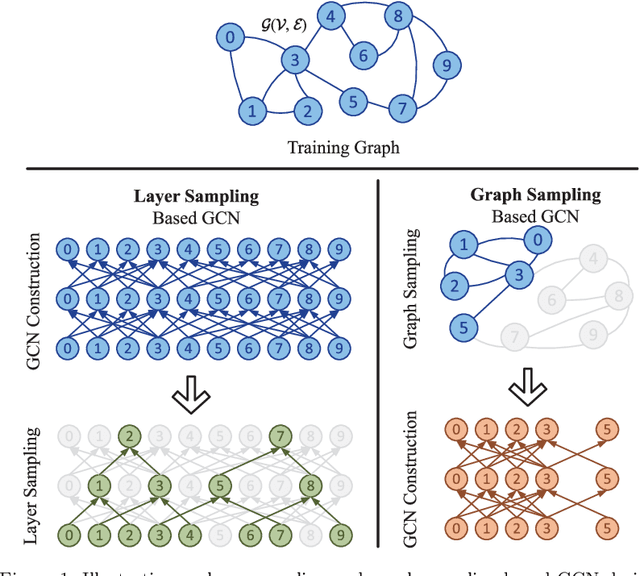

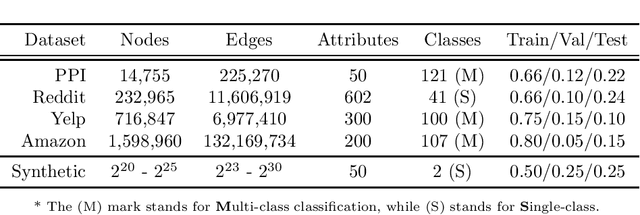
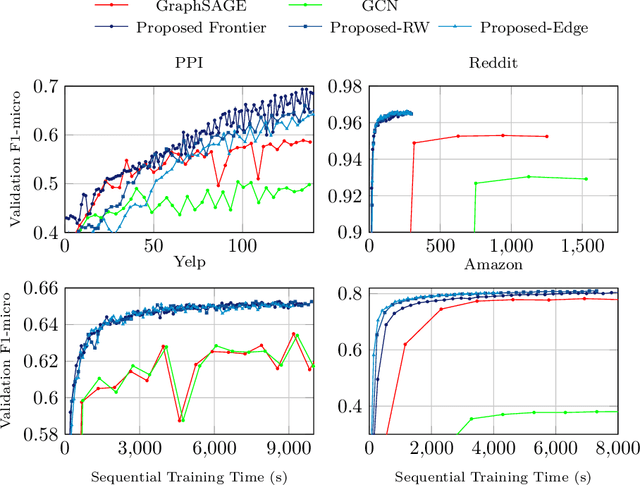
Graph Neural Networks (GNNs) are powerful deep learning models to generate node embeddings on graphs. When applying deep GNNs on large graphs, it is still challenging to perform training in an efficient and scalable way. We propose a novel parallel training framework. Through sampling small subgraphs as minibatches, we reduce training workload by orders of magnitude compared with state-of-the-art minibatch methods. We then parallelize the key computation steps on tightly-coupled shared memory systems. For graph sampling, we exploit parallelism within and across sampler instances, and propose an efficient data structure supporting concurrent accesses from samplers. The parallel sampler theoretically achieves near-linear speedup with respect to number of processing units. For feature propagation within subgraphs, we improve cache utilization and reduce DRAM traffic by data partitioning. Our partitioning is a 2-approximation strategy for minimizing the communication cost compared to the optimal. We further develop a runtime scheduler to reorder the training operations and adjust the minibatch subgraphs to improve parallel performance. Finally, we generalize the above parallelization strategies to support multiple types of GNN models and graph samplers. The proposed training outperforms the state-of-the-art in scalability, efficiency and accuracy simultaneously. On a 40-core Xeon platform, we achieve 60x speedup (with AVX) in the sampling step and 20x speedup in the feature propagation step, compared to the serial implementation. Our algorithm enables fast training of deeper GNNs, as demonstrated by orders of magnitude speedup compared to the Tensorflow implementation. We open-source our code at https://github.com/GraphSAINT/GraphSAINT.