 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial attacks on audio source separation
Paper and Code
Oct 09, 2020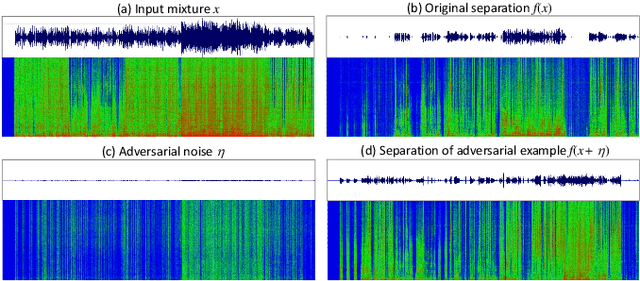

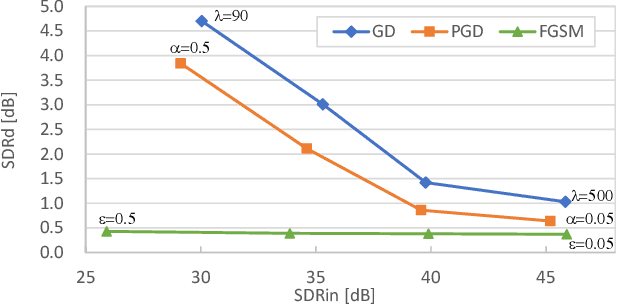
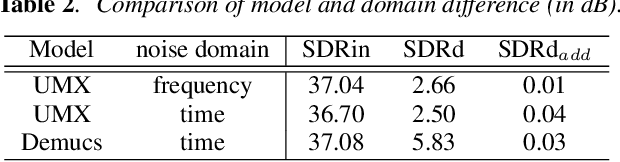
Despite the excellent performance of neural-network-based audio source separation methods and their wide range of applications, their robustness against intentional attacks has been largely neglected. In this work, we reformulate various adversarial attack methods for the audio source separation problem and intensively investigate them under different attack conditions and target models. We further propose a simple yet effective regularization method to obtain imperceptible adversarial noise while maximizing the impact on separation quality with low computational complexity. Experimental results show that it is possible to largely degrade the separation quality by adding imperceptibly small noise when the noise is crafted for the target model. We also show the robustness of source separation models against a black-box attack. This study provides potentially useful insights for developing content protection methods against the abuse of separated signals and improving the separation performance and robustness.