 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Monocular Depth Estimation with Semantic-aware Depth Features
Paper and Code
Oct 13, 2020
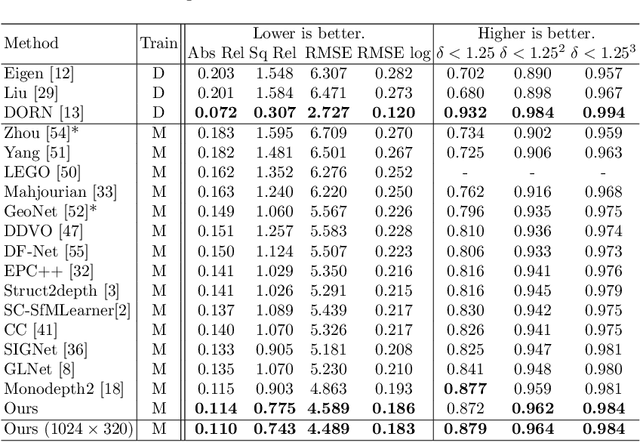
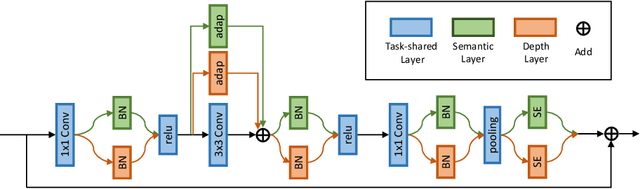
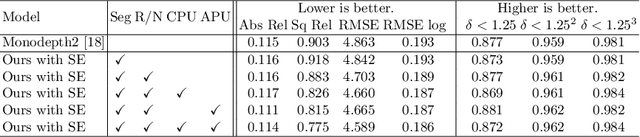
Self-supervised monocular depth estimation has emerged as a promising method because it does not require groundtruth depth maps during training. As an alternative for the groundtruth depth map, the photometric loss enables to provide self-supervision on depth prediction by matching the input image frames. However, the photometric loss causes various problems, resulting in less accurate depth values compared with supervised approaches. In this paper, we propose SAFENet that is designed to leverage semantic information to overcome the limitations of the photometric loss. Our key idea is to exploit semantic-aware depth features that integrate the semantic and geometric knowledge. Therefore, we introduce multi-task learning schemes to incorporate semantic-awareness into the representation of depth features. Experiments on KITTI dataset demonstrate that our methods compete or even outperform the state-of-the-art methods. Furthermore, extensive experiments on different datasets show its better generalization ability and robustness to various conditions, such as low-light or adverse weather.