 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Social Reinforcement Learning Improves Generalization
Paper and Code
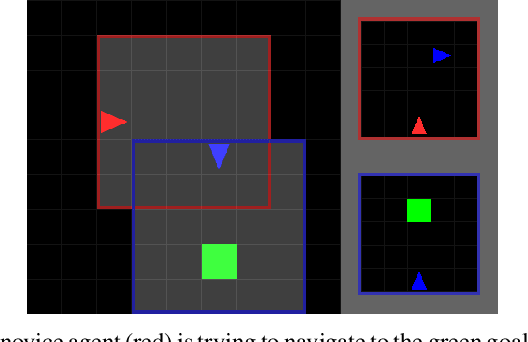
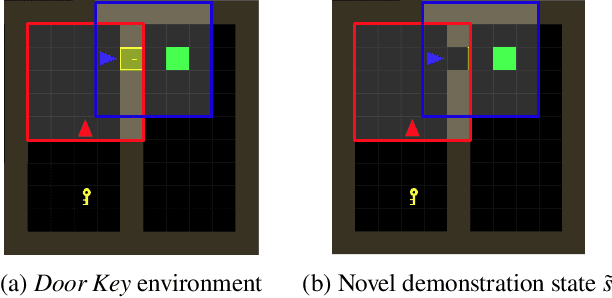
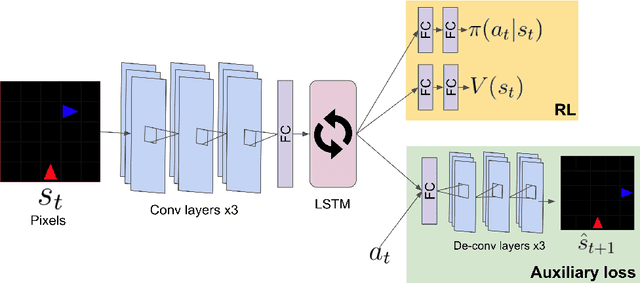
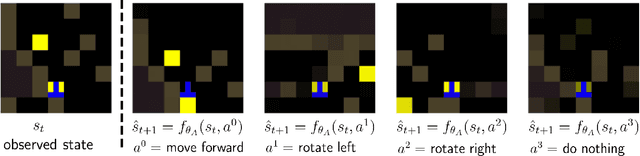
Social learning is a key component of human and animal intelligence. By taking cues from the behavior of experts in their environment, social learners can acquire sophisticated behavior and rapidly adapt to new circumstances. This paper investigates whether independent reinforcement learning (RL) agents in a multi-agent environment can use social learning to improve their performance using cues from other agents. We find that in most circumstances, vanilla model-free RL agents do not use social learning, even in environments in which individual exploration is expensive. We analyze the reasons for this deficiency, and show that by introducing a model-based auxiliary loss we are able to train agents to lever-age cues from experts to solve hard exploration tasks. The generalized social learning policy learned by these agents allows them to not only outperform the experts with which they trained, but also achieve better zero-shot transfer performance than solo learners when deployed to novel environments with experts. In contrast, agents that have not learned to rely on social learning generalize poorly and do not succeed in the transfer task. Further,we find that by mixing multi-agent and solo training, we can obtain agents that use social learning to out-perform agents trained alone, even when experts are not avail-able. This demonstrates that social learning has helped improve agents' representation of the task itself. Our results indicate that social learning can enable RL agents to not only improve performance on the task at hand, but improve generalization to novel environments.