 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Detail-Fidelity Attention Network for Single Image Super-Resolution
Paper and Code


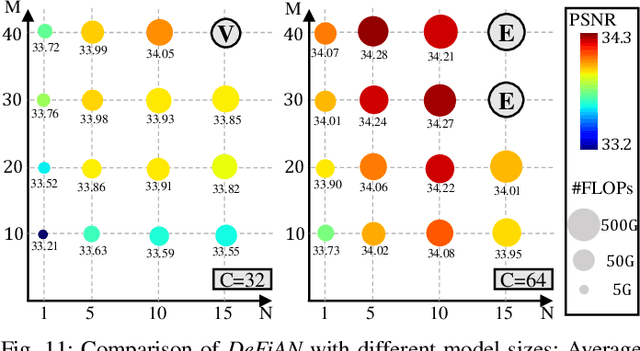
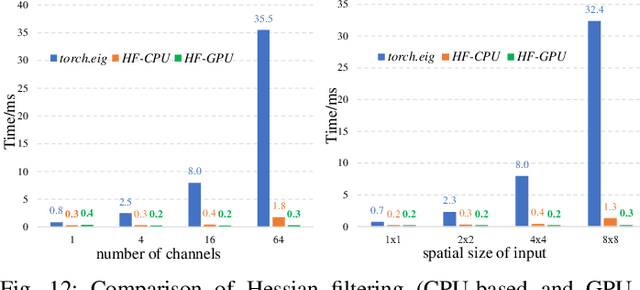
Benefiting from the strong capabilities of deep CNNs for feature representation and nonlinear mapping, deep-learning-based methods have achieved excellent performance in single image super-resolution. However, most existing SR methods depend on the high capacity of networks which is initially designed for visual recognition, and rarely consider the initial intention of super-resolution for detail fidelity. Aiming at pursuing this intention, there are two challenging issues to be solved: (1) learning appropriate operators which is adaptive to the diverse characteristics of smoothes and details; (2) improving the ability of model to preserve the low-frequency smoothes and reconstruct the high-frequency details. To solve them, we propose a purposeful and interpretable detail-fidelity attention network to progressively process these smoothes and details in divide-and-conquer manner, which is a novel and specific prospect of image super-resolution for the purpose on improving the detail fidelity, instead of blindly designing or employing the deep CNNs architectures for merely feature representation in local receptive fields. Particularly, we propose a Hessian filtering for interpretable feature representation which is high-profile for detail inference, a dilated encoder-decoder and a distribution alignment cell to improve the inferred Hessian features in morphological manner and statistical manner respectively. Extensive experiments demonstrate that the proposed methods achieve superior performances over the state-of-the-art methods quantitatively and qualitatively. Code is available at https://github.com/YuanfeiHuang/DeFiAN.