 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pre-training for Biomedical Question Answering
Paper and Code
Sep 27, 2020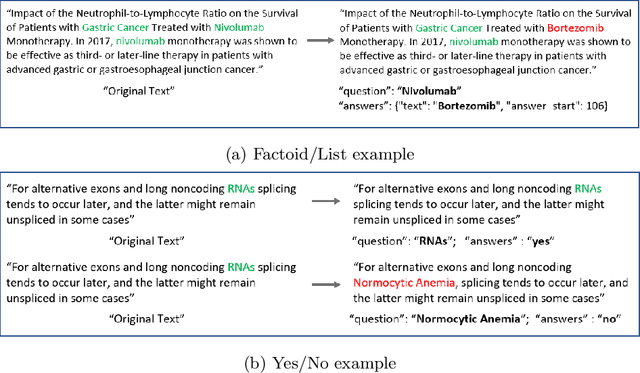
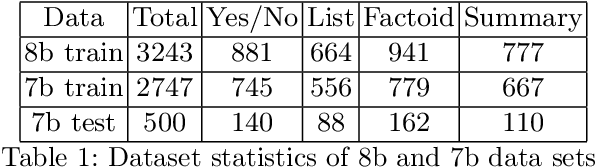
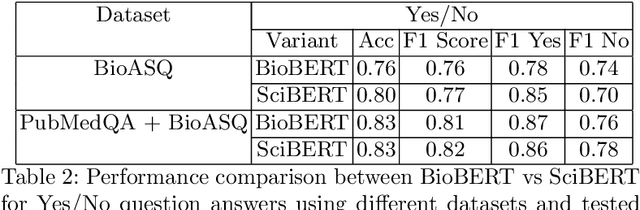
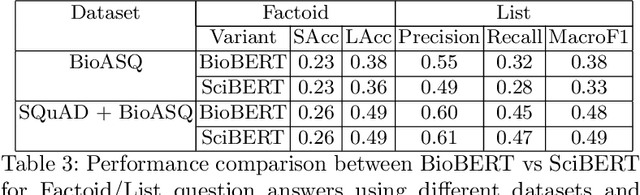
We explore the suitability of unsupervised representation learning methods on biomedical text -- BioBERT, SciBERT, and BioSentVec -- for biomedical question answering. To further improve unsupervised representations for biomedical QA, we introduce a new pre-training task from unlabeled data designed to reason about biomedical entities in the context. Our pre-training method consists of corrupting a given context by randomly replacing some mention of a biomedical entity with a random entity mention and then querying the model with the correct entity mention in order to locate the corrupted part of the context. This de-noising task enables the model to learn good representations from abundant, unlabeled biomedical text that helps QA tasks and minimizes the train-test mismatch between the pre-training task and the downstream QA tasks by requiring the model to predict spans. Our experiments show that pre-training BioBERT on the proposed pre-training task significantly boosts performance and outperforms the previous best model from the 7th BioASQ Task 7b-Phase B challenge.