 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Deep Multi-modal Network for Medical Visual Question Answering
Paper and Code

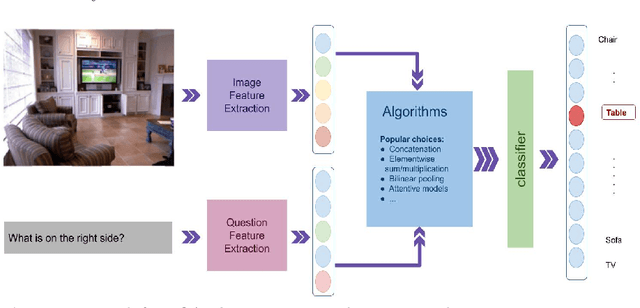
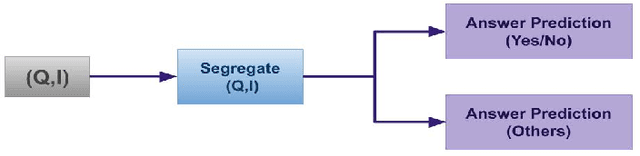
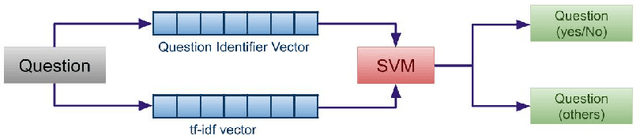
Visual Question Answering in Medical domain (VQA-Med) plays an important role in providing medical assistance to the end-users. These users are expected to raise either a straightforward question with a Yes/No answer or a challenging question that requires a detailed and descriptive answer. The existing techniques in VQA-Med fail to distinguish between the different question types sometimes complicates the simpler problems, or over-simplifies the complicated ones. It is certainly true that for different question types, several distinct systems can lead to confusion and discomfort for the end-users. To address this issue, we propose a hierarchical deep multi-modal network that analyzes and classifies end-user questions/queries and then incorporates a query-specific approach for answer prediction. We refer our proposed approach as Hierarchical Question Segregation based Visual Question Answering, in short HQS-VQA. Our contributions are three-fold, viz. firstly, we propose a question segregation (QS) technique for VQAMed; secondly, we integrate the QS model to the hierarchical deep multi-modal neural network to generate proper answers to the queries related to medical images; and thirdly, we study the impact of QS in Medical-VQA by comparing the performance of the proposed model with QS and a model without QS. We evaluate the performance of our proposed model on two benchmark datasets, viz. RAD and CLEF18. Experimental results show that our proposed HQS-VQA technique outperforms the baseline models with significant margins. We also conduct a detailed quantitative and qualitative analysis of the obtained results and discover potential causes of errors and their solutions.