 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Medical Annotation Quality to Decrease Labeling Burden Using Stratified Noisy Cross-Validation
Paper and Code
Sep 22, 2020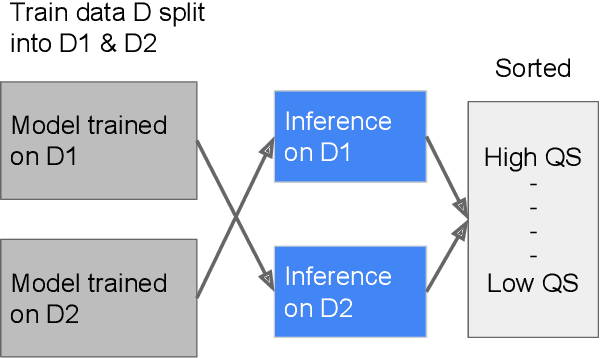

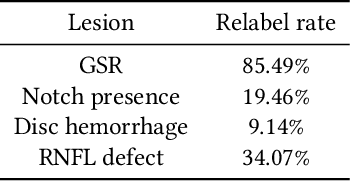
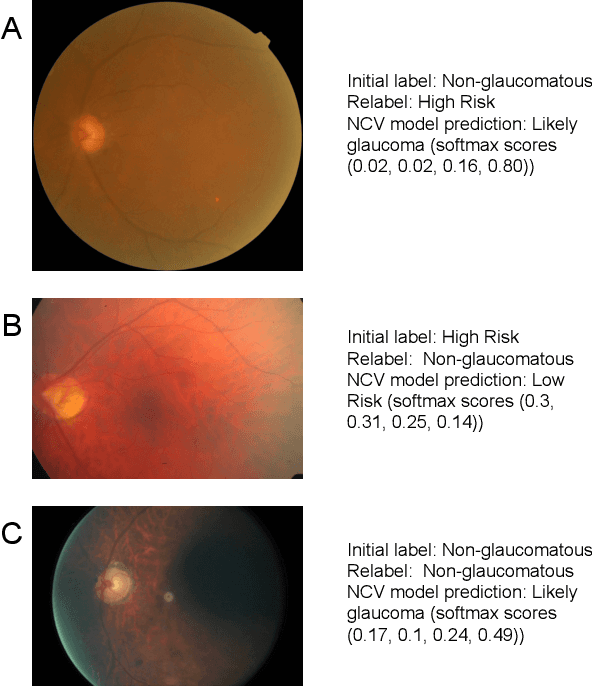
As machine learning has become increasingly applied to medical imaging data, noise in training labels has emerged as an important challenge. Variability in diagnosis of medical images is well established; in addition, variability in training and attention to task among medical labelers may exacerbate this issue. Methods for identifying and mitigating the impact of low quality labels have been studied, but are not well characterized in medical imaging tasks. For instance, Noisy Cross-Validation splits the training data into halves, and has been shown to identify low-quality labels in computer vision tasks; but it has not been applied to medical imaging tasks specifically. In this work we introduce Stratified Noisy Cross-Validation (SNCV), an extension of noisy cross validation. SNCV can provide estimates of confidence in model predictions by assigning a quality score to each example; stratify labels to handle class imbalance; and identify likely low-quality labels to analyze the causes. We assess performance of SNCV on diagnosis of glaucoma suspect risk from retinal fundus photographs, a clinically important yet nuanced labeling task. Using training data from a previously-published deep learning model, we compute a continuous quality score (QS) for each training example. We relabel 1,277 low-QS examples using a trained glaucoma specialist; the new labels agree with the SNCV prediction over the initial label >85% of the time, indicating that low-QS examples mostly reflect labeler errors. We then quantify the impact of training with only high-QS labels, showing that strong model performance may be obtained with many fewer examples. By applying the method to randomly sub-sampled training dataset, we show that our method can reduce labelling burden by approximately 50% while achieving model performance non-inferior to using the full dataset on multiple held-out test sets.