 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeed-Forward On-Edge Fine-tuning Using Static Synthetic Gradient Modules
Paper and Code
Sep 21, 2020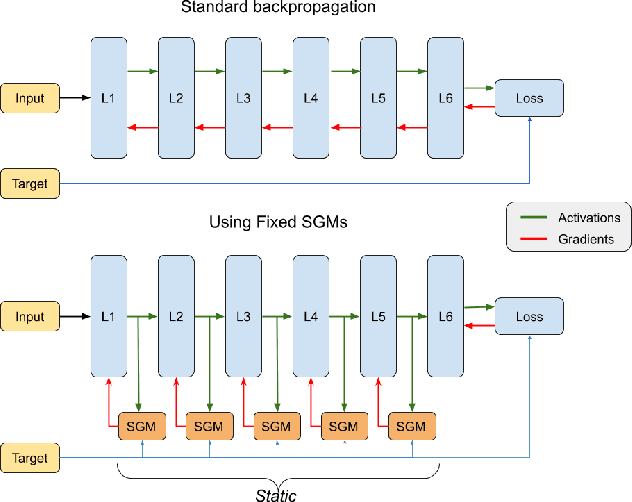
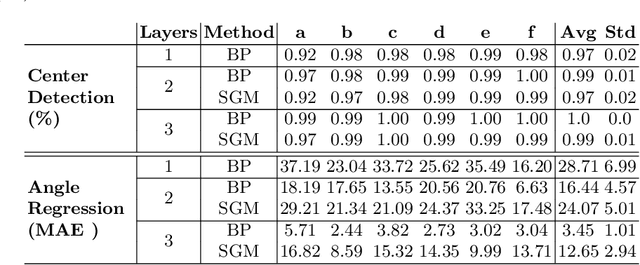
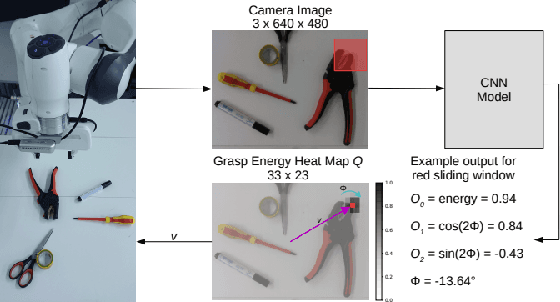
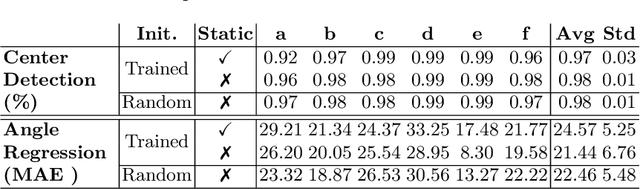
Training deep learning models on embedded devices is typically avoided since this requires more memory, computation and power over inference. In this work, we focus on lowering the amount of memory needed for storing all activations, which are required during the backward pass to compute the gradients. Instead, during the forward pass, static Synthetic Gradient Modules (SGMs) predict gradients for each layer. This allows training the model in a feed-forward manner without having to store all activations. We tested our method on a robot grasping scenario where a robot needs to learn to grasp new objects given only a single demonstration. By first training the SGMs in a meta-learning manner on a set of common objects, during fine-tuning, the SGMs provided the model with accurate gradients to successfully learn to grasp new objects. We have shown that our method has comparable results to using standard backpropagation.