 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Low Precision Graph Neural Networks
Paper and Code
Sep 19, 2020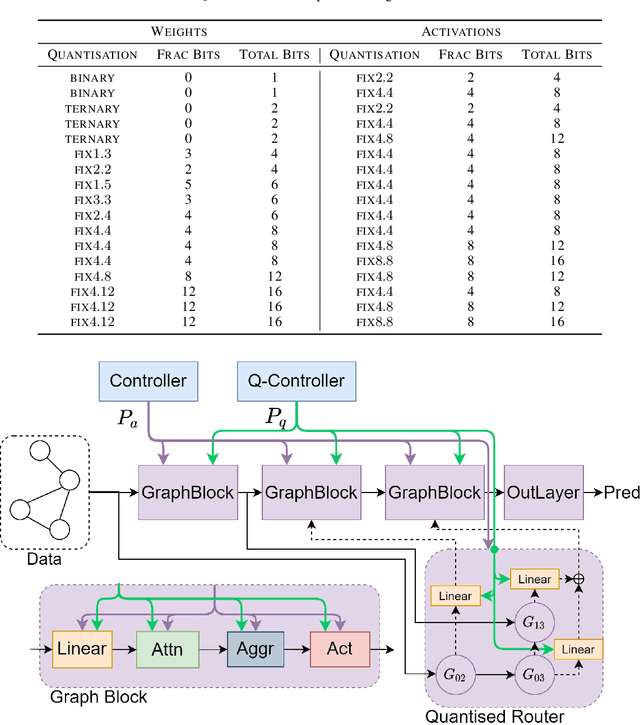


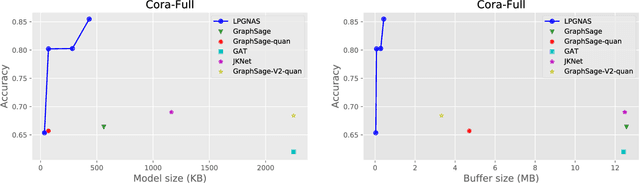
Deep Graph Neural Networks (GNNs) show promising performance on a range of graph tasks, yet at present are costly to run and lack many of the optimisations applied to DNNs. We show, for the first time, how to systematically quantise GNNs with minimal or no loss in performance using Network Architecture Search (NAS). We define the possible quantisation search space of GNNs. The proposed novel NAS mechanism, named Low Precision Graph NAS (LPGNAS), constrains both architecture and quantisation choices to be differentiable. LPGNAS learns the optimal architecture coupled with the best quantisation strategy for different components in the GNN automatically using back-propagation in a single search round. On eight different datasets, solving the task of classifying unseen nodes in a graph, LPGNAS generates quantised models with significant reductions in both model and buffer sizes but with similar accuracy to manually designed networks and other NAS results. In particular, on the Pubmed dataset, LPGNAS shows a better size-accuracy Pareto frontier compared to seven other manual and searched baselines, offering a 2.3 times reduction in model size but a 0.4% increase in accuracy when compared to the best NAS competitor. Finally, from our collected quantisation statistics on a wide range of datasets, we suggest a W4A8 (4-bit weights, 8-bit activations) quantisation strategy might be the bottleneck for naive GNN quantisations.