 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FaceChannel: A Fast & Furious Deep Neural Network for Facial Expression Recognition
Paper and Code
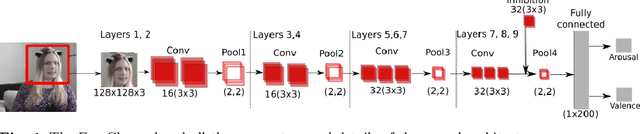
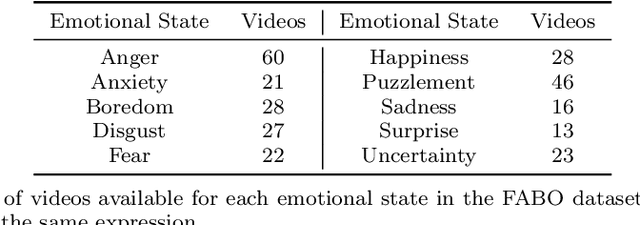
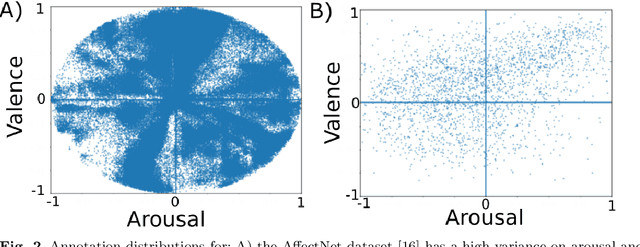
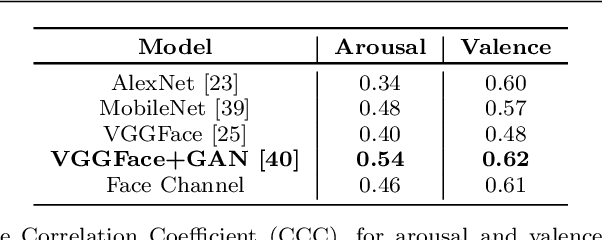
Current state-of-the-art models for automatic Facial Expression Recognition (FER) are based on very deep neural networks that are effective but rather expensive to train. Given the dynamic conditions of FER, this characteristic hinders such models of been used as a general affect recognition. In this paper, we address this problem by formalizing the FaceChannel, a light-weight neural network that has much fewer parameters than common deep neural networks. We introduce an inhibitory layer that helps to shape the learning of facial features in the last layer of the network and thus improving performance while reducing the number of trainable parameters. To evaluate our model, we perform a series of experiments on different benchmark datasets and demonstrate how the FaceChannel achieves a comparable, if not better, performance to the current state-of-the-art in FER. Our experiments include cross-dataset analysis, to estimate how our model behaves on different affective recognition conditions. We conclude our paper with an analysis of how FaceChannel learns and adapt the learned facial features towards the different datasets.