 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient and Scalable Acceleration of Online Decision Tree Learning on FPGA
Paper and Code
Sep 03, 2020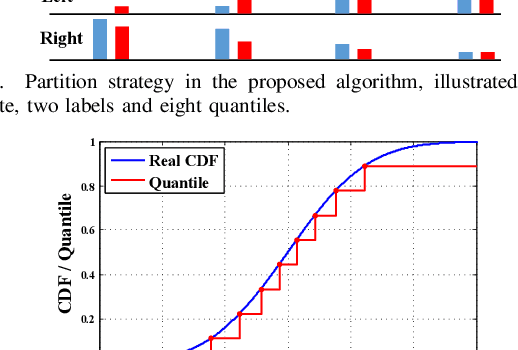
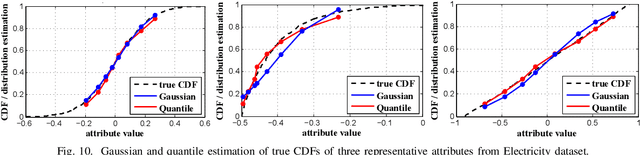

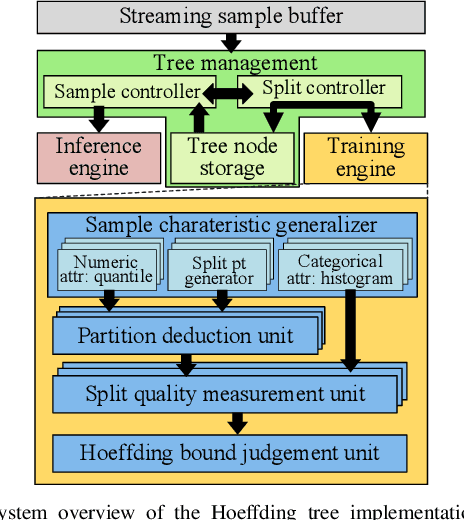
Decision trees are machine learning models commonly used in various application scenarios. In the era of big data, traditional decision tree induction algorithms are not suitable for learning large-scale datasets due to their stringent data storage requirement. Online decision tree learning algorithms have been devised to tackle this problem by concurrently training with incoming samples and providing inference results. However, even the most up-to-date online tree learning algorithms still suffer from either high memory usage or high computational intensity with dependency and long latency, making them challenging to implement in hardware. To overcome these difficulties, we introduce a new quantile-based algorithm to improve the induction of the Hoeffding tree, one of the state-of-the-art online learning models. The proposed algorithm is light-weight in terms of both memory and computational demand, while still maintaining high generalization ability. A series of optimization techniques dedicated to the proposed algorithm have been investigated from the hardware perspective, including coarse-grained and fine-grained parallelism, dynamic and memory-based resource sharing, pipelining with data forwarding. We further present a high-performance, hardware-efficient and scalable online decision tree learning system on a field-programmable gate array (FPGA) with system-level optimization techniques. Experimental results show that our proposed algorithm outperforms the state-of-the-art Hoeffding tree learning method, leading to 0.05% to 12.3% improvement in inference accuracy. Real implementation of the complete learning system on the FPGA demonstrates a 384x to 1581x speedup in execution time over the state-of-the-art design.