 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Chinese Dependency Parser Based on A Large-scale Dataset
Paper and Code
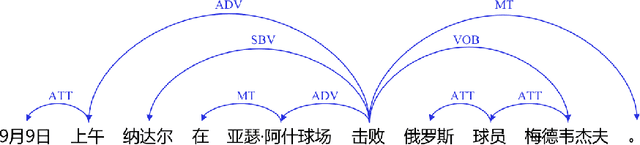
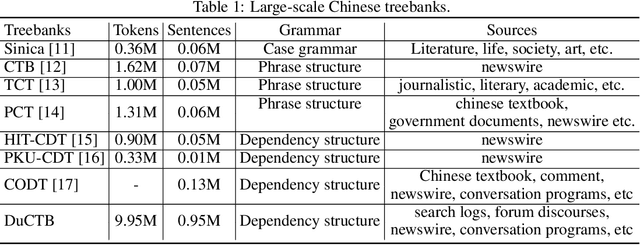
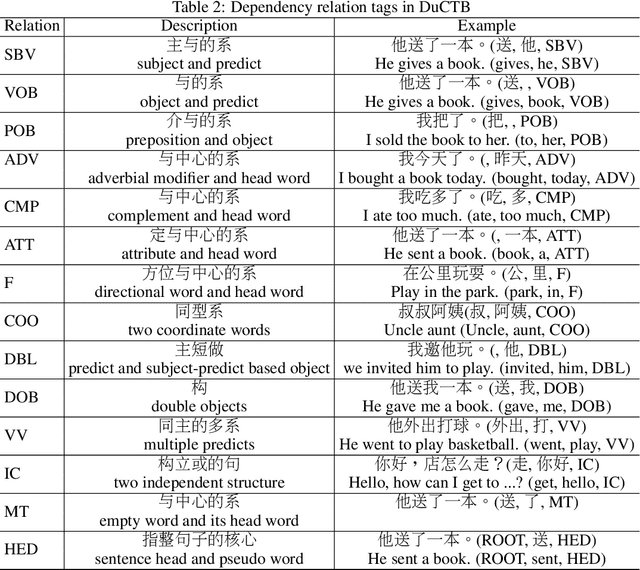
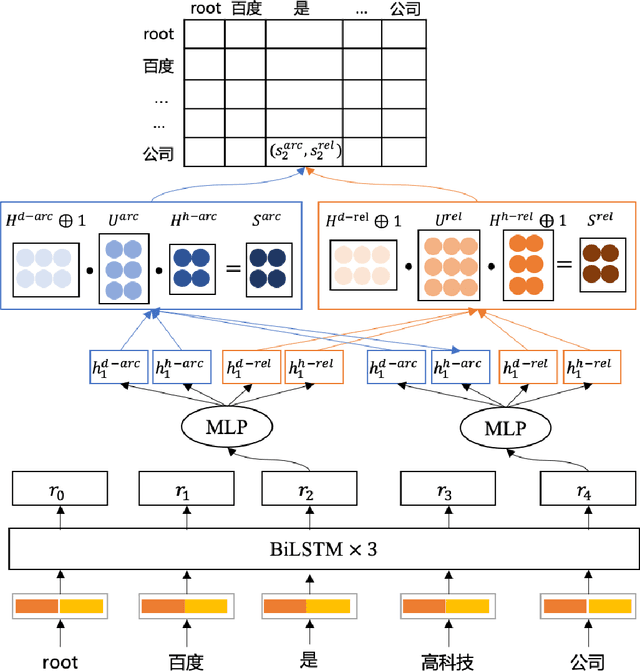
Dependency parsing is a longstanding natural language processing task, with its outputs crucial to various downstream tasks. Recently, neural network based (NN-based) dependency parsing has achieved significant progress and obtained the state-of-the-art results. As we all know, NN-based approaches require massive amounts of labeled training data, which is very expensive because it requires human annotation by experts. Thus few industrial-oriented dependency parser tools are publicly available. In this report, we present Baidu Dependency Parser (DDParser), a new Chinese dependency parser trained on a large-scale manually labeled dataset called Baidu Chinese Treebank (DuCTB). DuCTB consists of about one million annotated sentences from multiple sources including search logs, Chinese newswire, various forum discourses, and conversation programs. DDParser is extended on the graph-based biaffine parser to accommodate to the characteristics of Chinese dataset. We conduct experiments on two test sets: the standard test set with the same distribution as the training set and the random test set sampled from other sources, and the labeled attachment scores (LAS) of them are 92.9% and 86.9% respectively. DDParser achieves the state-of-the-art results, and is released at https://github.com/baidu/DDParser.