 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperPAL: Supervised Proposition ALignment for Multi-Document Summarization and Derivative Sub-Tasks
Paper and Code


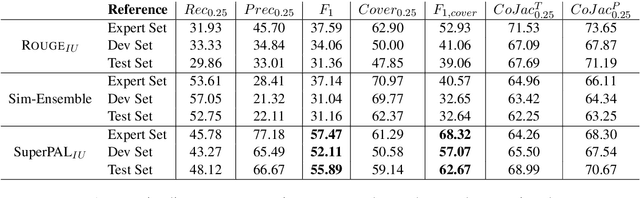
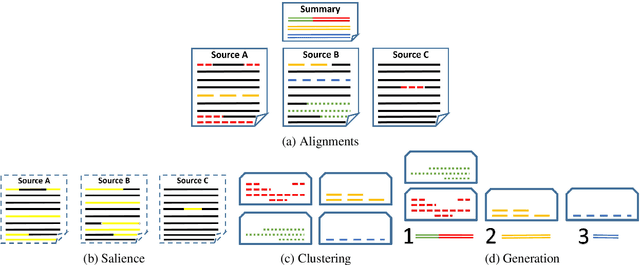
Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by generation. While alignment of spans between reference summaries and source documents has been leveraged for training component tasks, the underlying alignment step was never independently addressed or evaluated. We advocate developing high quality source-reference alignment algorithms, that can be applied to recent large-scale datasets to obtain useful "silver", i.e. approximate, training data. As a first step, we present an annotation methodology by which we create gold standard development and test sets for summary-source alignment, and suggest its utility for tuning and evaluating effective alignment algorithms, as well as for properly evaluating MDS subtasks. Second, we introduce a new large-scale alignment dataset for training, with which an automatic alignment model was trained. This aligner achieves higher coherency with the reference summary than previous aligners used for summarization, and gets significantly higher ROUGE results when replacing a simpler aligner in a competitive summarization model. Finally, we release three additional datasets (for salience, clustering and generation), naturally derived from our alignment datasets. Furthermore, these datasets can be derived from any summarization dataset automatically after extracting alignments with our trained aligner. Hence, they can be utilized for training summarization sub-tasks.