 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Encoding -- Design Provably More Powerful Graph Neural Networks for Structural Representation Learning
Paper and Code

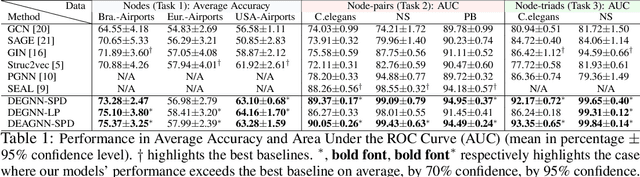
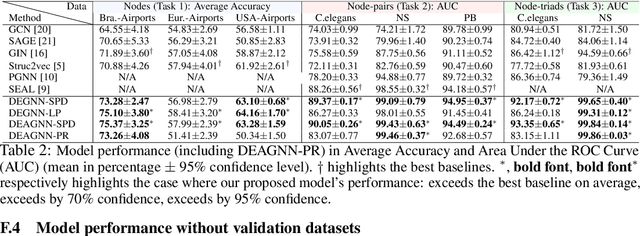
Learning structural representations of node sets from graph-structured data is crucial for applications ranging from node-role discovery to link prediction and molecule classification. Graph Neural Networks (GNNs) have achieved great success in structural representation learning. However, most GNNs are limited by the 1-Weisfeiler-Lehman (WL) test and thus possible to generate identical representation for structures and graphs that are actually different. More powerful GNNs, proposed recently by mimicking higher-order-WL tests, only focus on entire-graph representations and cannot utilize sparsity of the graph structure to be computationally efficient. Here we propose a general class of structure-related features, termed Distance Encoding (DE), to assist GNNs in representing node sets with arbitrary sizes with strictly more expressive power than the 1-WL test. DE essentially captures the distance between the node set whose representation is to be learnt and each node in the graph, which includes important graph-related measures such as shortest-path-distance and generalized PageRank scores. We propose two general frameworks for GNNs to use DEs (1) as extra node attributes and (2) further as controllers of message aggregation in GNNs. Both frameworks may still utilize the sparse structure to keep scalability to process large graphs. In theory, we prove that these two frameworks can distinguish node sets embedded in almost all regular graphs where traditional GNNs always fail. We also rigorously analyze their limitations. Empirically, we evaluate these two frameworks on node structural roles prediction, link prediction and triangle prediction over six real networks. The results show that our models outperform GNNs without DEs by up-to 15% improvement in average accuracy and AUC. Our models also significantly outperform other SOTA baselines particularly designed for those tasks.