 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQutNocturnal@HASOC'19: CNN for Hate Speech and Offensive Content Identification in Hindi Language
Paper and Code
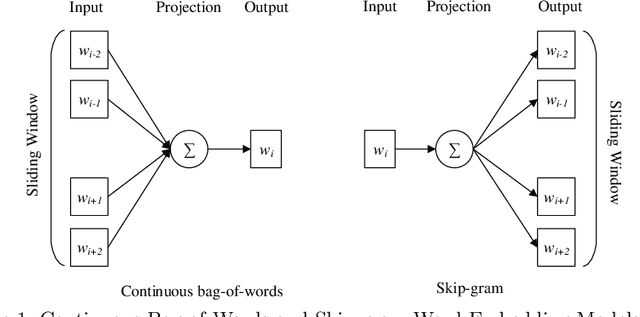
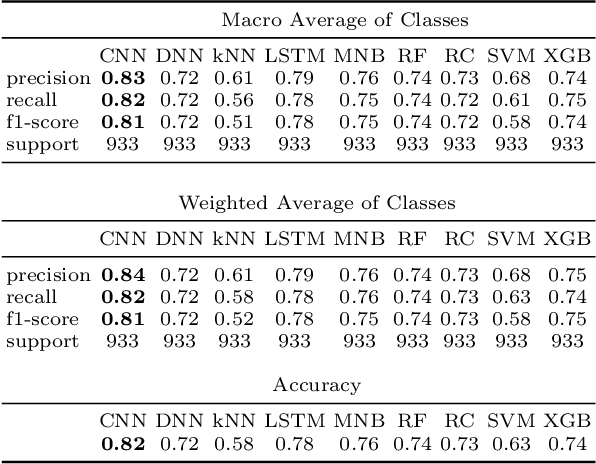
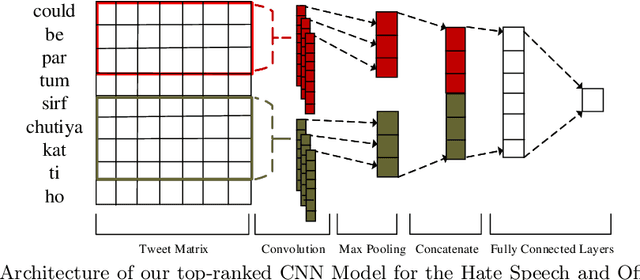
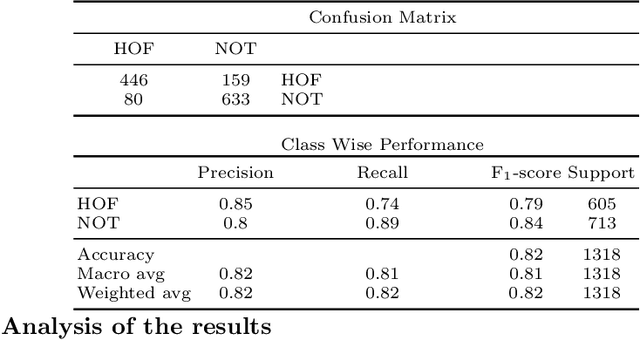
We describe our top-team solution to Task 1 for Hindi in the HASOC contest organised by FIRE 2019. The task is to identify hate speech and offensive language in Hindi. More specifically, it is a binary classification problem where a system is required to classify tweets into two classes: (a) \emph{Hate and Offensive (HOF)} and (b) \emph{Not Hate or Offensive (NOT)}. In contrast to the popular idea of pretraining word vectors (a.k.a. word embedding) with a large corpus from a general domain such as Wikipedia, we used a relatively small collection of relevant tweets (i.e. random and sarcasm tweets in Hindi and Hinglish) for pretraining. We trained a Convolutional Neural Network (CNN) on top of the pretrained word vectors. This approach allowed us to be ranked first for this task out of all teams. Our approach could easily be adapted to other applications where the goal is to predict class of a text when the provided context is limited.