 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Action Recognition with Embedded Key Point Shifts
Paper and Code
Aug 26, 2020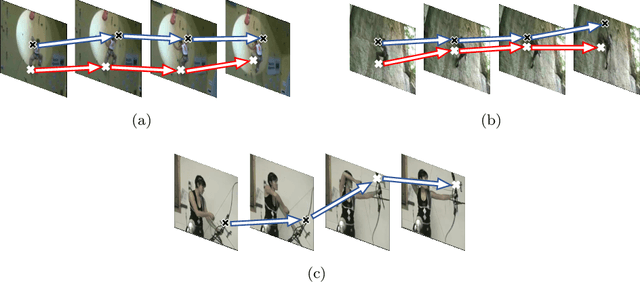
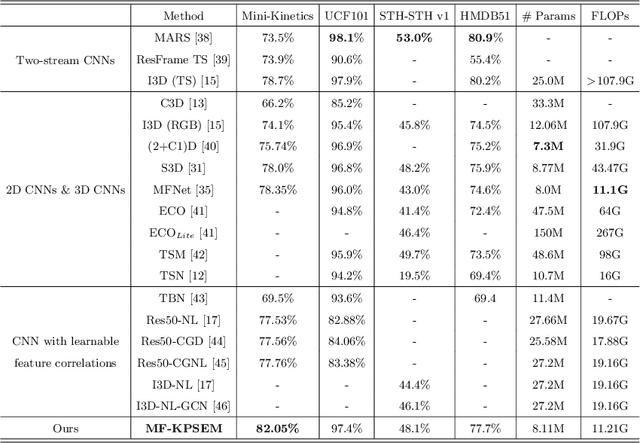
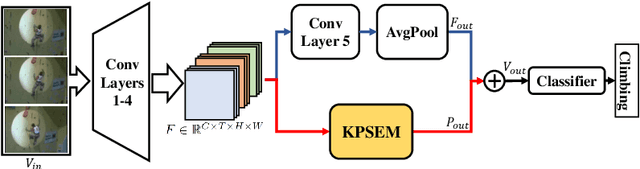
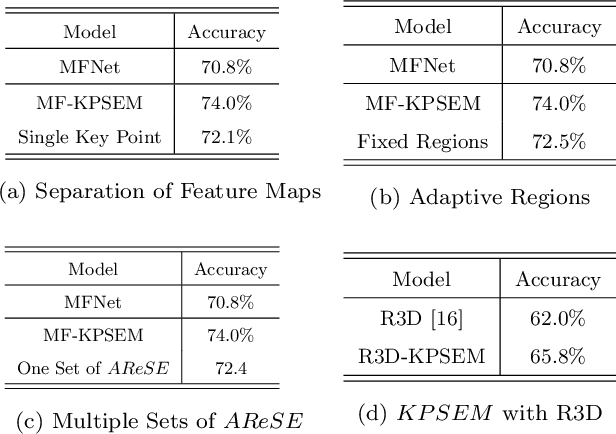
Temporal feature extraction is an essential technique in video-based action recognition. Key points have been utilized in skeleton-based action recognition methods but they require costly key point annotation. In this paper, we propose a novel temporal feature extraction module, named Key Point Shifts Embedding Module ($KPSEM$), to adaptively extract channel-wise key point shifts across video frames without key point annotation for temporal feature extraction. Key points are adaptively extracted as feature points with maximum feature values at split regions, while key point shifts are the spatial displacements of corresponding key points. The key point shifts are encoded as the overall temporal features via linear embedding layers in a multi-set manner. Our method achieves competitive performance through embedding key point shifts with trivial computational cost, achieving the state-of-the-art performance of 82.05% on Mini-Kinetics and competitive performance on UCF101, Something-Something-v1, and HMDB51 datasets.