 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-local Enhancement Network for NMFs-aware Sign Language Recognition
Paper and Code

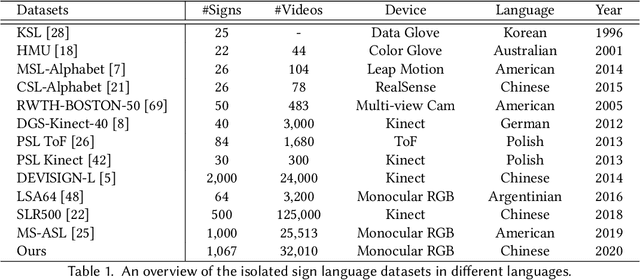

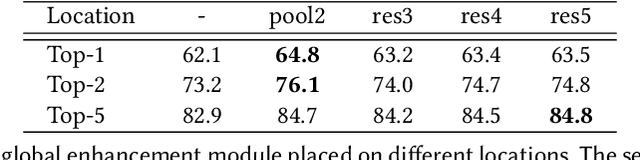
Sign language recognition (SLR) is a challenging problem, involving complex manual features, i.e., hand gestures, and fine-grained non-manual features (NMFs), i.e., facial expression, mouth shapes, etc. Although manual features are dominant, non-manual features also play an important role in the expression of a sign word. Specifically, many sign words convey different meanings due to non-manual features, even though they share the same hand gestures. This ambiguity introduces great challenges in the recognition of sign words. To tackle the above issue, we propose a simple yet effective architecture called Global-local Enhancement Network (GLE-Net), including two mutually promoted streams towards different crucial aspects of SLR. Of the two streams, one captures the global contextual relationship, while the other models the discriminative fine-grained cues. Moreover, due to the lack of datasets explicitly focusing on this kind of features, we introduce the first non-manual features-aware isolated Chinese sign language dataset (NMFs-CSL) with a total vocabulary size of 1,067 sign words in daily life. Extensive experiments on NMFs-CSL and SLR500 datasets demonstrate the effectiveness of our method.