 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Intrinsic Differential Privacy of Bagging
Paper and Code
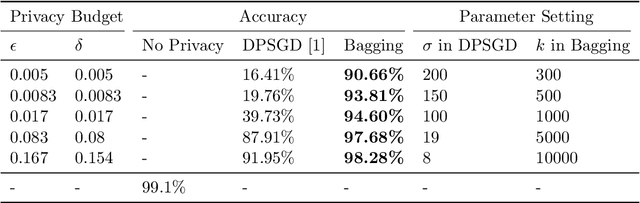
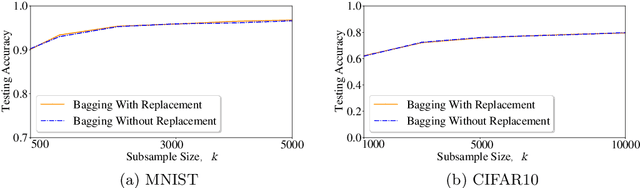
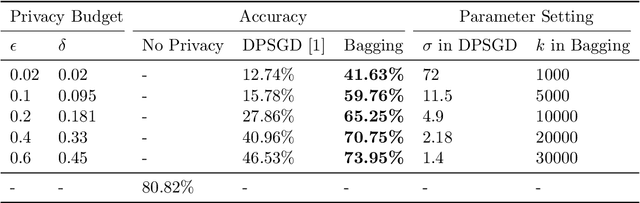
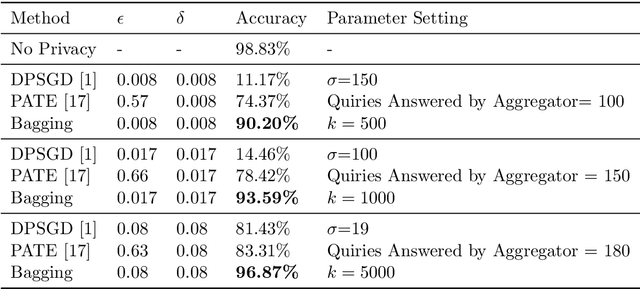
Differentially private machine learning trains models while protecting privacy of the sensitive training data. The key to obtain differentially private models is to introduce noise/randomness to the training process. In particular, existing differentially private machine learning methods add noise to the training data, the gradients, the loss function, and/or the model itself. Bagging, a popular ensemble learning framework, randomly creates some subsamples of the training data, trains a base model for each subsample using a base learner, and takes majority vote among the base models when making predictions. Bagging has intrinsic randomness in the training process as it randomly creates subsamples. Our major theoretical results show that such intrinsic randomness already makes Bagging differentially private without the needs of additional noise. In particular, we prove that, for any base learner, Bagging with and without replacement respectively achieves $\left(N\cdot k \cdot \ln{\frac{n+1}{n}},1- (\frac{n-1}{n})^{N\cdot k}\right)$-differential privacy and $\left(\ln{\frac{n+1}{n+1-N\cdot k}}, \frac{N\cdot k}{n} \right)$-differential privacy, where $n$ is the training data size, $k$ is the subsample size, and $N$ is the number of base models. Moreover, we prove that if no assumptions about the base learner are made, our derived privacy guarantees are tight. We empirically evaluate Bagging on MNIST and CIFAR10. Our experimental results demonstrate that Bagging achieves significantly higher accuracies than state-of-the-art differentially private machine learning methods with the same privacy budgets.